

The database has 8,000 profiles. The req opens. The recruiter starts a fresh Boolean string anyway.
That gap, between the signal a team has already paid to collect and the cold-start work they default to every time, is where most candidate databases lose their value. The data is there. Nobody mines it.
The team re-pays for candidates they already engaged, re-screens people who already passed a loop, re-builds a sourcing brief from scratch for a role their own ATS could have surfaced in seconds.
A working candidate database is the signal layer recruiters mine first on every new req. The shift from storage tier to data layer is the move that makes the rest of the sourcing motion stack up properly.
Why the database keeps getting bypassed
Most recruiting teams have a candidate database. Most of those databases hold five-figure profile counts. Most of the time, when a new req opens, the database is the last place anyone looks.
The pattern is consistent. Search inside the ATS is sluggish, returns too many false positives, and surfaces stale profiles. Schemas vary by recruiter, by year, and by the platform that fed the data in.
The hiring manager has changed. The role spec has changed. The recruiter wasn't there for the last hiring round in this function. So the team defaults to the safer-feeling work: open LinkedIn Recruiter, start a fresh Boolean string, source from zero.
The cost is paid in time, sourcing spend, and the candidate experience of people who get re-contacted cold for a role they're already a strong match for in your own database.
The underlying problem is operational discipline. Until the team treats the database as a layer they mine first on every req, the volume of profiles is just storage no one trusts.
Stop treating the database like storage
The reframe matters because it changes the operating question. A storage tier asks where do we put this? A data layer asks how does the team use this?
Same data, different posture. The disciplines that follow only make sense once the team has decided the database is a thing you USE, not a thing you HAVE.
The five disciplines in the next section are the storage-to-data-layer translation. Each one is a continuous practice the team owns, not a project that ships and ends.
Signal beats storage when every recruiter on the team can find the right candidate inside their own database in under a minute, and trusts what they find.
- Profiles re-keyed by hand at every touchpoint
- Inconsistent schemas across roles and recruiters
- Stale records, hygiene days that never happen
- Keyword filters miss the right person
- Queried as a fallback, after external sourcing
- Captured automatically from interviews and applications
- Standardized profile structure across the team
- Refreshes through use, not through hygiene days
- Natural-language search plus AI-suggested matches
- The first thing the team checks on every new req
The five disciplines that activate the data layer
The five disciplines below are sequenced from substrate to surface. Capture is the precondition. Standardize and refresh keep the underlying data trustable. Search and embed turn it into a tool the team reaches for daily.
The substrate, not the surface, is where most teams under-invest.
1. Capture automatically (don't re-key)
Manual data entry is the failure mode at the foundation. If a recruiter has to retype an interview summary into the ATS, the summary either doesn't land, lands incomplete, or lands inconsistently across the team.
The fix is automated capture. Resume parsing, AI Notetaker on every interview, ATS sync on candidate progression, structured feedback forms in the workflow itself.
The discipline is structural, not behavioral. Don't ask recruiters to remember to update the database. Build the database so it updates as the recruiter does the work.
2. Standardize the schema
Candidates that don't compare cleanly don't surface in search. Standardize the profile structure across the team: same skills taxonomy, same competency rubric, same scorecard shape, same role-fit fields.
The schema is the basis of every comparison the database will run. Inconsistency at this layer poisons every downstream query.
If your team uses different scorecard formats per function, pick one canonical structure and migrate the rest. The day-one cost is real. The every-day-after benefit is that any recruiter can search across any function and trust the result.
3. Keep it fresh through use
The teams that hold quarterly hygiene days rarely run them. The teams that don't run them ship stale databases. Both lose.
The third path is refreshing the database through use itself. Every time a recruiter touches a profile, the touch carries fresh context: a new interview, a new conversation, a new piece of feedback, a new outcome.
If you've built automated intake and standardization right, refresh-through-use is a side effect of doing the work. Profiles get more accurate as the team uses them, not less.
4. Make it instantly searchable
The search interface IS the database, for the recruiter using it. If finding the right candidate takes ten clicks and three filter passes, the database doesn't function as a data layer. If it takes one natural-language query, it does.
The bar for the search experience is the bar for the database. Modern search means asking show me senior backend engineers who interviewed for the Stripe Connect-type role and asked thoughtful questions about reliability in plain text and getting a ranked list.
Less than that, and the team defaults back to external sourcing.
5. Embed it in the workflow
The last discipline closes the loop. Checking the database on every new req has to be a workflow step, not a recruiter preference.
The standing rule: open the database first, surface internal matches, see who's already engaged. If three qualified candidates land inside 24 hours, you may not need external sourcing at all.
Embedding it in the workflow is the move that activates the previous four disciplines. The intake, the schema, the freshness, the search all earn their place by being used. The data layer becomes infrastructure, not optional tooling.
What AI changes about the database
Four shifts. Static storage to dynamic matching. Manual tagging to automatic understanding. Outdated profiles to continuously improving signal. Recruiter-typed search to AI-suggested candidates.
The cumulative effect is static storage to active matching, which is the difference between a database you query and a database that surfaces candidates against new reqs without being asked.
According to Metaview's 2026 AI Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, the multiplier on this shift is large.
The multiplier grows because the database becomes a shared instrument rather than a recruiter-only tool.
When the database surfaces the right candidates against the right roles automatically, the conversation between recruiters and hiring managers shifts from who can we find? to which of these three already-engaged candidates moves first?
The data layer is the common ground.
How Metaview turns your database into a sourcing engine
Metaview activates the database across three surfaces. AI Sourcing mines the records you already have. Application Review surfaces the existing-pool match on every new inbound. Reports shows the patterns in your own data so the next sourcing brief is informed by the last loop.
The three surfaces together are the data-layer activation. None of them ask the recruiter to do more manual work. Each one turns the data the team has already collected into a hire decision faster.
AI Sourcing queries the database in natural language. Ask for a senior backend engineer who interviewed for a Connect-type role and asked thoughtful reliability questions, and the system returns a ranked candidate list, drawn from the profiles the team already paid to build.
The whole pool becomes searchable the way a recruiter thinks.
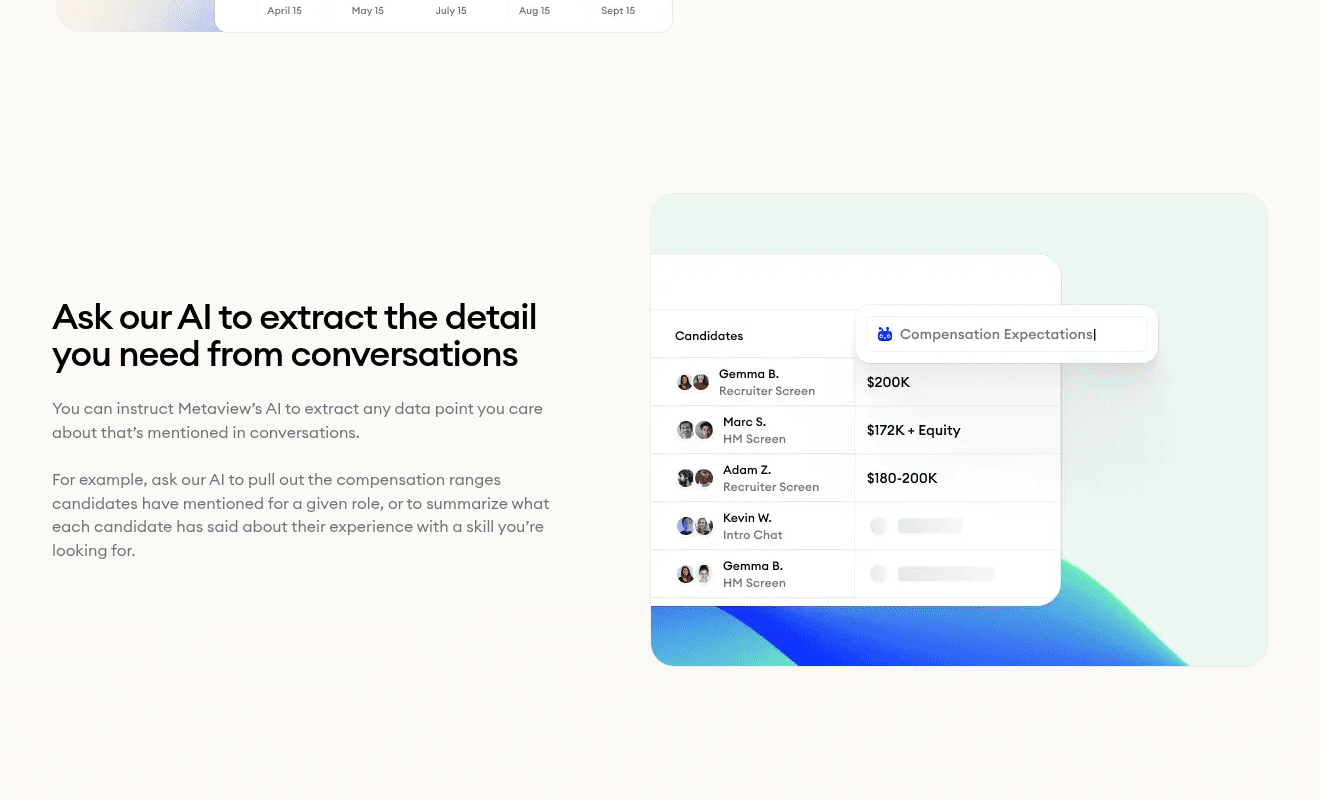
- 1Natural-language query box, type the role criteria the way a recruiter would speak them.
- 2Existing ATS records are the search corpus, not an external network.
- 3Ranked candidates surface with the matching signal highlighted in the interview notes.
Application Review reverses the flow. New inbound lands, and the system checks the existing-pool match before the recruiter does anything.
If a candidate already in the database fits the new role better than a brand-new applicant, that gets surfaced. The data layer volunteers the answer rather than waiting to be queried.
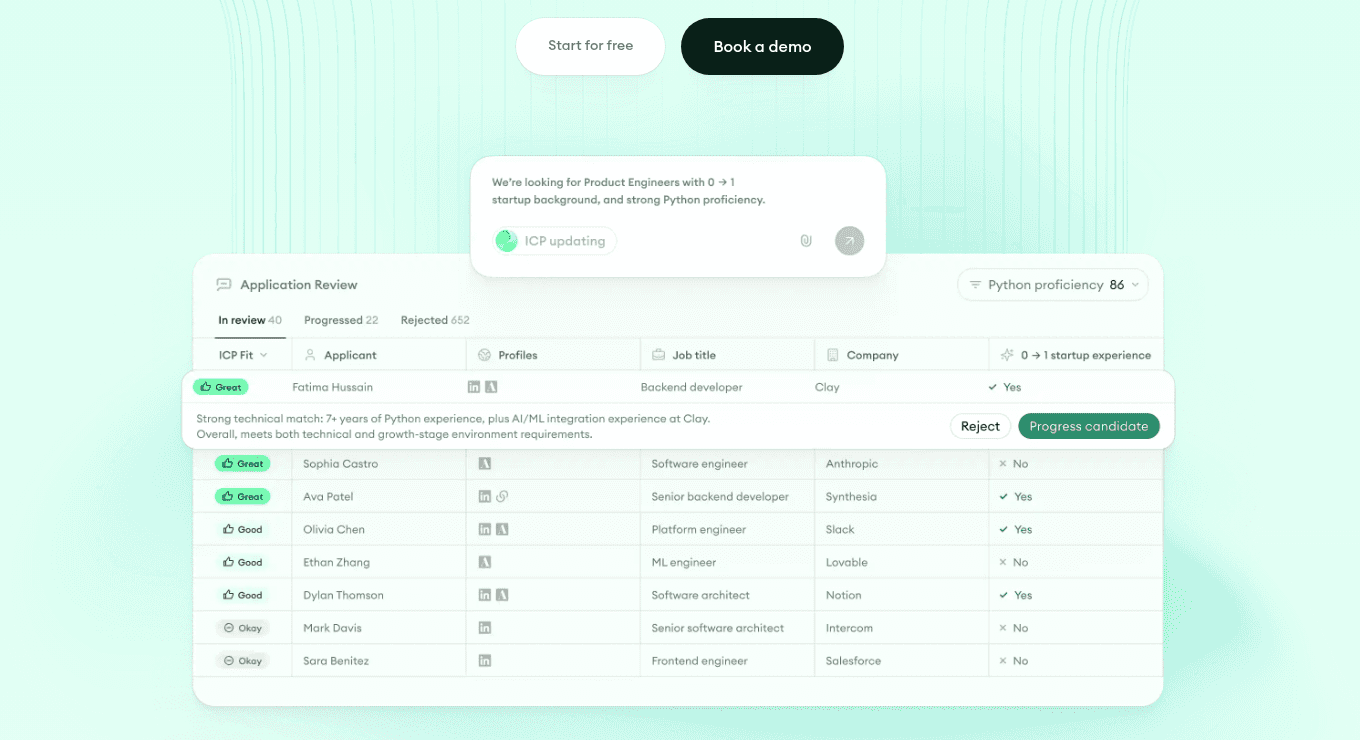
- 1ICP-fit flags surface against the role context, not just keyword match.
- 2Reasoning trail shows why a candidate was matched, drawn from prior interview signal.
- 3Progress or reject actions land directly on the candidate record, updating the data layer.
Reports closes the loop on the database itself. The patterns across past hires become inputs to the next sourcing brief: which channels produced the strongest signal, which competencies predicted success, which interview signals correlated with quality of hire.
The database becomes the input to the next decision, not just the storage layer for the last one.
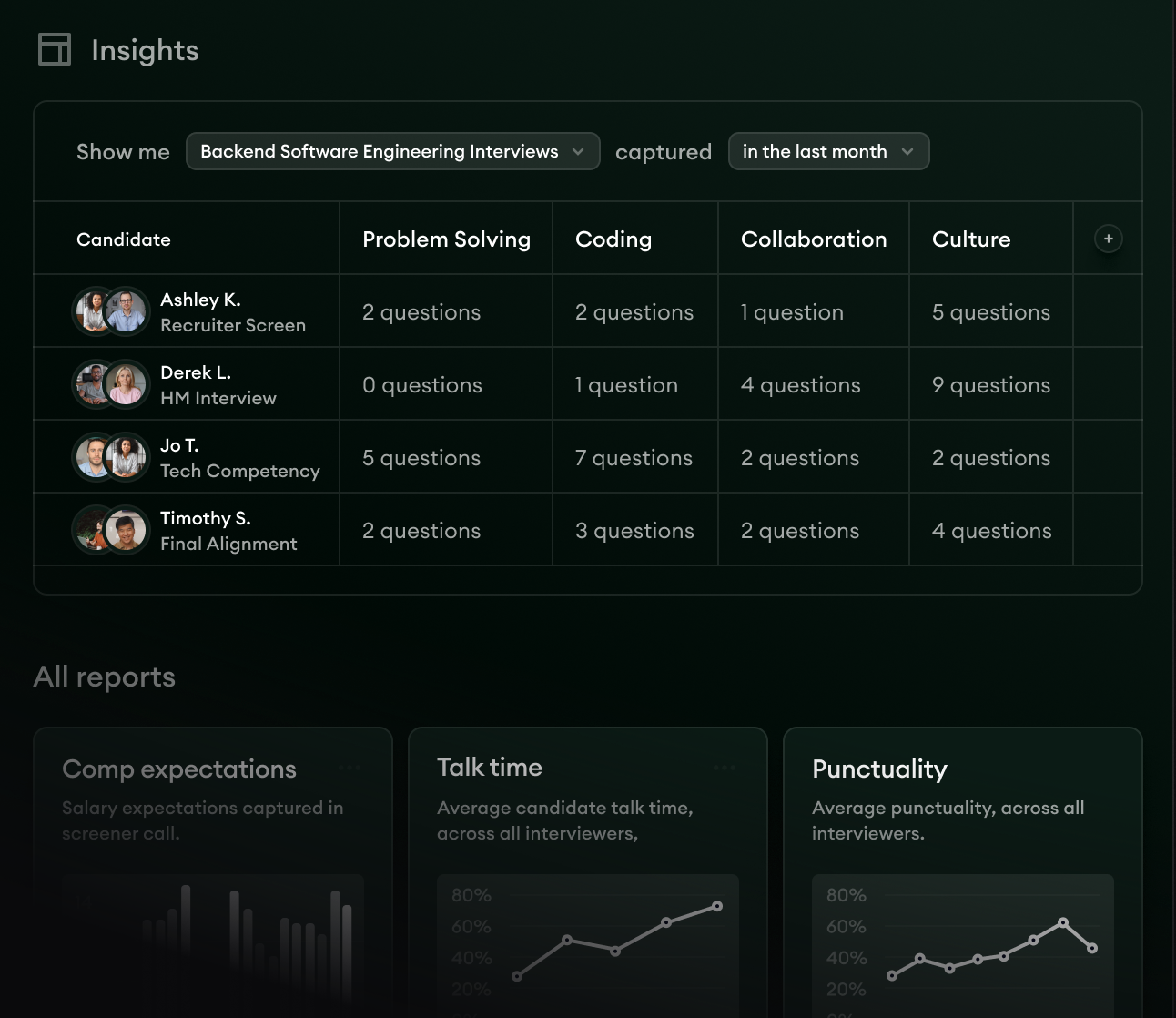
- 1Competency-level reads across every interview the team has run.
- 2Patterns surface across roles and channels, not just per-candidate.
- 3The next sourcing brief gets informed by the last loop's signal automatically.
The combined effect is what teams running this configuration describe firsthand. Raines International moved from gut-feel sourcing to evidence-based matching once the database stopped being a passive archive.
We elevated from gut-feel recommendations to evidence-based insights, creating a faster, clearer, and more data-driven experience for everyone involved. Every scorecard and report looks and sounds consistent, regardless of who prepared it.”
The consistency is the data-layer effect. When the underlying records are standardized and the search is intelligent, recommendations become trustable across recruiters, functions, and hiring rounds. That's what turns the database from overhead into a hiring engine.
Teams that mine the data layer first hire faster, spend less on outbound, and protect the candidate experience of people they've already engaged.
The database becomes foundational, not nice-to-have, in the same way structured interview notes shifted from a recruiter habit into an operational expectation.
The data layer is the foundation every other sourcing motion draws from, including hiring-pool nurture, ATS rediscovery, and outbound campaigns.
Once it's set up, you stop opening reqs cold. The team that mines first spends less time sourcing, sees lower cost per hire, and runs shorter time-to-hire cycles than the team that treats the database as a fallback.
The advantage builds because the data layer keeps accruing value with every interview.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Frequently asked
What's the difference between a candidate database and an ATS?
An ATS is the workflow engine for active reqs: stages, statuses, communications. The candidate database is the substrate that ATS data lives on. Most ATSes ship with a queryable database underneath, but treat it as a storage tier. The data-layer reframe is about how your team uses what's already there, not which platform holds it.
How often should we mine the database before going external?
On every new req, before any external channel opens. The operational rule is a 24-hour internal-match window: if three qualified candidates from the database don't surface within 24 hours of req open, then escalate to external sourcing. Most teams find the first qualified match inside the first hour once search is set up right.
What about candidates from 18+ months ago, are they still useful?
Yes, with a re-verify step. Anyone touched more than 12 months ago needs availability and current-role confirmed before re-engagement. The matching should run against current role requirements, not the role the candidate applied for. AI Sourcing handles the re-verify step automatically by pulling fresh signal across the public profile network.
Can a small team maintain a large database without burnout?
When intake is automated and search is AI-powered, a single recruiter can maintain 5,000 to 10,000 database entries without manual hygiene work. Without automation, the practical ceiling is closer to 500 to 800 before the upkeep loop breaks. The bottleneck is the manual layer, not the size of the database.
Does Metaview's AI Sourcing pull from our existing ATS, or build a separate database?
Bi-directional with your ATS, not a separate database. Supported integrations include Ashby, Greenhouse, Bullhorn, Lever, SmartRecruiters, and Workday, plus calendar and video providers. AI Sourcing writes back into the ATS so the data layer sits on your records, not next to them. ATS updates flow back into Metaview, keeping everything in sync.