

The debrief after a panel decays the same way every time. Someone says they liked the candidate. Someone else says she felt a bit off. Nobody can quite remember what she said on the third question, the one that was supposed to test the thing the role lives or dies on.
By Thursday afternoon, the rubric you needed gets rebuilt from memory. The verdict ends up anchored to whoever talked last and loudest. Six months later, when the hire works or doesn't, you can't trace back to why.
The fix runs in the other direction. Define what an excellent, good, and bad response looks like before the question is asked, score against that scaffold while the conversation is fresh, and roll the evidence into one verdict the next interviewer can read.
Below is the workflow that gets the rubric on paper before the panel runs, gets it scored in the room, and gets the verdict out of someone's memory and into a record. The Metaview surfaces that take the manual lift off each move are named where they fit.
How to write and score the rubric
The workflow runs from intake to verdict. Each move pairs a rubric step with the Metaview surface that absorbs the manual work behind it. The judgment stays with the interviewer. The bookkeeping doesn't.
1. Align with the hiring manager on the skills the role demands
You can't grade a response if you haven't named the skills the response is meant to test.
The first move is the intake call with the hiring manager. A focused conversation that surfaces what day-one success looks like, what can be developed over the first six months, and what's truly non-negotiable.
Get specific. "Java programming" is non-negotiable for a backend role. "Adaptability" is non-negotiable for a startup founding-team hire. "Stakeholder communication" is non-negotiable for a senior PM. A rubric you write from a vague skill list grades against vague criteria.
AI Notes captures the intake call automatically, then lands a structured skill summary in the post-meeting view. The summary is the artifact you build the rubric from.
No re-transcription, no recall pass, no follow-up email asking what the hiring manager meant by "a self-starter."
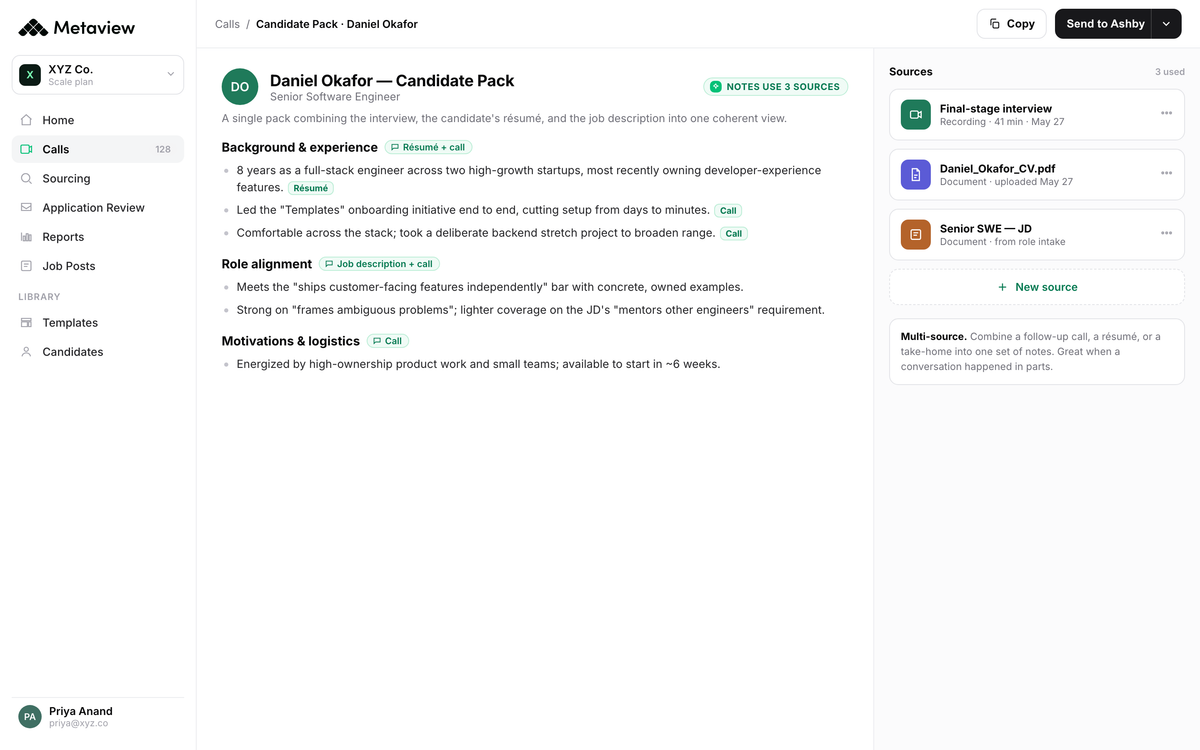
2. Build the question set from the skills, not the resume
With the skill list in hand, the question set follows quickly. Behavioral and situational prompts that draw out the specific skills you named. Resume-walk questions take a back seat, because the resume is the candidate's framing, not yours.
Three soft skills come up on almost every role: problem-solving, attention to detail, and communication. The strongest behavioral prompts for each force a candidate into a real example, not an abstract claim.
The table below is a starter set. Extend it with the skills specific to your role.
| Skill | Question |
|---|---|
| Problem-solving | "Describe a time you solved a problem without input from a senior team member." |
| "Tell me about a complex issue you addressed before it escalated." | |
| "Walk me through a problem you solved with limited resources or information." | |
| Attention to detail | "Give me an example of attention to detail materially changing a project outcome." |
| "Tell me about a small oversight that could have escalated, and how you caught it." | |
| "When did your meticulous approach prevent a risk the team didn't see?" | |
| Communication | "Describe explaining a complex concept to a diverse stakeholder group." |
| "Tell me about a moment where clear communication made the outcome possible." | |
| "How do you approach explaining technical depth to a non-technical audience?" |
Add rows for the skills your role demands: stakeholder management, code review, customer empathy, whatever it is. If you can't link a question to a Step 1 skill, drop it. Skills first, questions second, not the other way around.
3. Pre-write the rubric for each question
The rubric is the answer to one question: what does a great answer to this question look like? Pre-write it. Before the panel runs. Per question.
For a problem-solving question, the three-tier scaffold looks like this. Use the dimensions in the left column as a template you can apply to any behavioral question.
| What to look for | Excellent | Good | Bad |
|---|---|---|---|
| Context | A specific situation, not a hypothetical | Some context, less depth | Vague or superficial |
| Structure | STAR (or an equivalent) arc, clean | Loose, but recognizable | Disorganized, no logical flow |
| Analysis | Names what they considered and ruled out | Basic reasoning, light on detail | No insight into their thinking |
| Ownership | Personal role explicit | Personal contribution implied | Personal role unclear |
| Outcome | Quantified, linked to their actions | Mentioned, not directly linked | Missing or detached from actions |
| Reflection | What they learned, what they'd do differently | Some takeaways mentioned | None |
Write the three-tier scaffold per question before the panel. Share it with every interviewer. Excellent, good, bad, pre-written is what makes the score in Step 4 fast and consistent. Reconstructing the rubric at debrief is exactly the failure mode this step removes.
4. Score in the room, against the rubric
The fastest decay in interview signal happens in the first 24 hours. The interviewer's memory of which specific answer hit which specific tier fades.
By the second day, the scorecard gets back-filled with general impressions: "strong on problem-solving," "a bit weak on communication." Useless at the debrief.
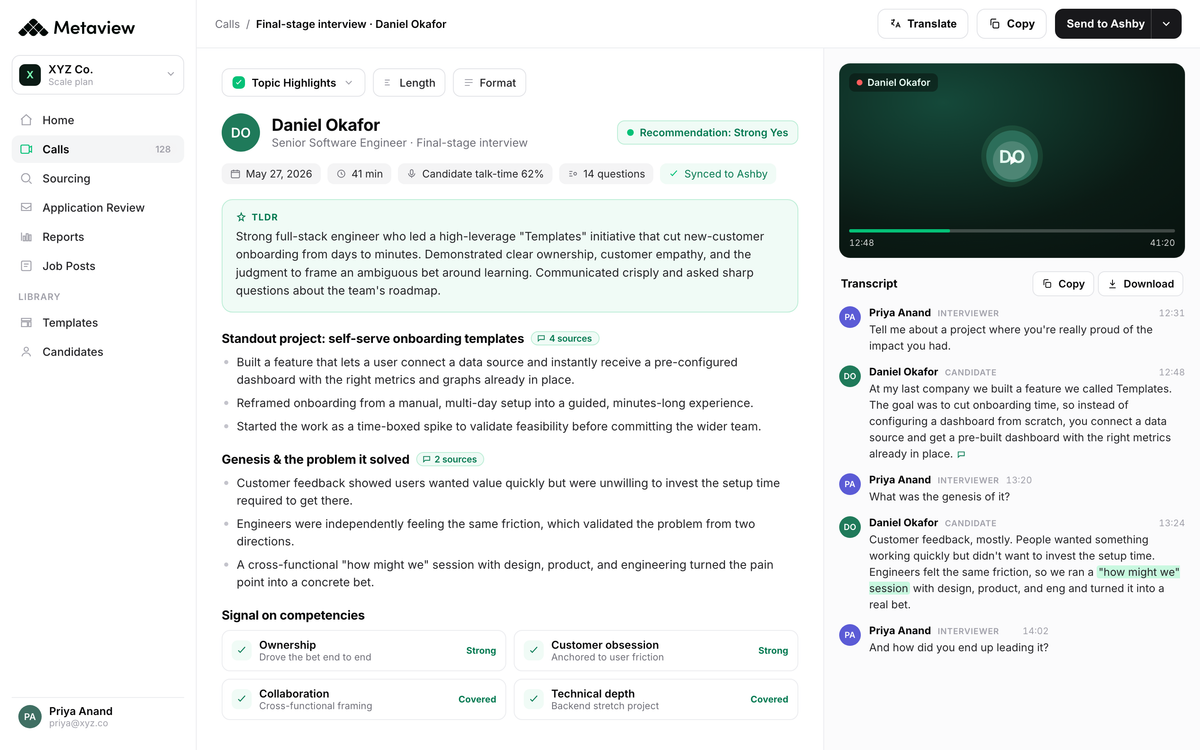
Score in the moment, while the conversation is fresh. The interviewer doesn't break flow to type. AI Notes captures the response verbatim and lands a rubric-aligned scorecard in the post-meeting view.
The interviewer reviews, adjusts where the AI got it close-but-not-quite, and submits in under five minutes after the call.
The score sits against the candidate record in Application Review, alongside the ICP-fit signal from intake and the rubric-anchored quotes from every other panel round. The next interviewer can read the prior round's rubric scoring before they even open the candidate's resume.
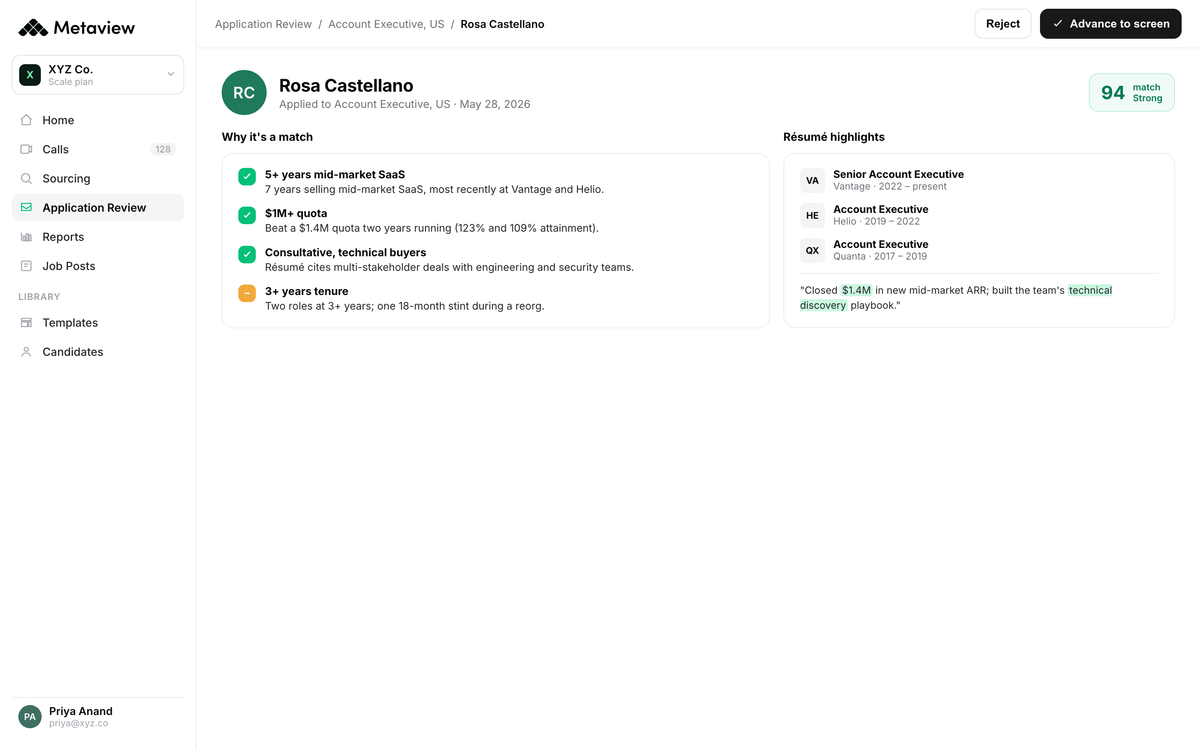
5. Synthesize across rounds into a defensible verdict
A four-person panel produces four rubric scores per candidate. The debrief used to mean re-litigating what each interviewer thought.
Multi-Source Summaries combine the four scores, the rubric-anchored quotes, and the consistency signal into a single brief the team reads together at debrief.
The brief surfaces where the panel agrees, where they don't, and which specific response in the transcript backs each rubric score. If two interviewers gave the same response a different score, that becomes the conversation, not a debate about who remembers the answer better.
The verdict gets defensible across the panel. Six months in, when you need to explain why you passed on her or why you hired him, the rubric-anchored record is the audit trail.
The decision didn't run on vibes. It ran on evidence anchored to specific responses, scored against the rubric you wrote before the panel saw the candidate's name.
Why this beats memory and gut feel
The shift from holistic debrief to rubric-anchored evidence isn't subtle. Same panel, same candidates, different infrastructure underneath. The rubric workflow trades the post-call reconstruction tax for one structured pass that lands while the answer is still fresh.
- Rubric reconstructed from memory at debrief
- Scores anchor to whoever talked last and loudest
- Four interviewers, four versions of the candidate
- No way to defend the pass six months out
- Calibration drift invisible until a hire fails
- Excellent / good / bad scaffold written before the panel
- Scores land in the room while answers are fresh
- One brief combining every round's rubric scores
- Rubric-anchored quotes back every verdict in the record
- Drift readable across the corpus via Reports
The teams that run this workflow describe the shift in the same language. The decision conversation runs on evidence, not impressions. The recruiter walks into the debrief with a brief everyone has read, not a question about who covered what.
We elevated from gut-feel recommendations to evidence-based insights, creating a faster, clearer, and more data-driven experience for everyone involved. Every scorecard and report looks and sounds consistent, regardless of who prepared it.”
What this looks like across the hiring stack
The rubric workflow isn't a stand-alone tool. It sits inside the broader quality-of-hire system Metaview powers: intake captured, panel calibrated, summaries rolled up, drift surfaced, postmortems closed.
The alignment between recruiters and hiring managers that the rubric forces, that's the operating layer of teams that hit their hiring goals. The data on the lift is direct.
That spread between 79% and 36% is the cost of the alignment gap. A pre-written rubric is one of the cheapest ways to close it on a single role.
Every question earns its rubric. The system you build around the rubric is the difference between a debrief that lands on evidence and one that lands on whose memory was louder.
This is the existing panel with a rubric written before the panel runs, scored while the conversation is fresh, and synthesized into a brief the team reads together. Not a separate workflow bolted on top.
Turn on AI Notes once for screening calls and panels. Pull rubric scoring into Application Review for the funnel. Bring the panel into the Multi-Source brief for the debrief. The rubric stops being an artifact you reconstruct and starts being one the system carries.
If you want to put the rubric workflow to work on a live role, book a walkthrough below. Or sign up free and try it on your next panel.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Frequently asked
Do I need a rubric for every interview question, or can I score holistically?
Per-question rubrics are what make the verdict defensible six months out, when someone asks why you passed on a strong candidate or why you hired one who later didn't work out. Holistic scoring leaves no audit trail, which is fine right up until you need one.
How do I keep the rubric consistent across interviewers running the same panel?
A 10-minute pre-panel calibration call gets every interviewer reading the same rubric the same way. Multi-Source Summaries then surface interviewer-to-interviewer drift across rounds, so the calibration call sharpens against real data rather than guesswork.
Where do the rubric scores live after the panel?
In Application Review against the candidate record, and pushed back into your ATS via the standard sync. Reports queries the scores across the corpus, so you can pull patterns across roles, interviewers, and time without re-keying anything.
How do I handle ambiguous or borderline responses?
Probe in the moment with a follow-up. Ask the candidate to walk you through the steps, give a concrete example, or describe what they ruled out. The follow-up exchange lands in the transcript, so the next interviewer can pick up the borderline thread on the next round rather than re-discovering it.
Can I score on phone screens, or only on Zoom and Teams panels?
Phone screens score the same way as a video panel. Capture works across PSTN, mobile, Zoom, Meet, and Teams, so the same rubric-aligned scorecard and quote evidence land regardless of channel. The early-stage signal doesn't fall off the funnel between screen and panel.
What if my hiring manager disagrees with the rubric at debrief?
Pull the rubric-anchored response evidence from the panel into the debrief and anchor the disagreement to the specific response, not interpretation. If the rubric needs to shift, you have a captured record showing where the prior calibration broke and a starting point for the next intake call.