

Talent density is the most-cited and least-instrumented concept in modern recruiting. Most teams can quote Reed Hastings on it. Almost none can tell you whether their last hire landed above or below their current median. The bar is real, it just lives in 12 interviewers' heads instead of in a system anyone can see.
That gap shows up in the data. 58% of recruiting leaders and hiring managers actively contemplate working around their counterpart, according to Metaview's 2026 AI & Hiring Alignment Report. When the two people who own the bar most directly are quietly routing around each other, the bar doesn't compound. It drifts.
The thesis of this guide: talent density is a measurement problem, not a philosophy problem. The only durable way to raise it is to instrument the interview itself, so the signal that justifies a hire today is the same signal you can audit, calibrate, and feed into the performance system six months from now. Six instrumented moves, one operating model, and a 30-day audit you can run this quarter.
What talent density actually is (and why most definitions miss the operating layer)
The standard definition: talent density is the concentration of high-performing, high-impact employees on a team. Netflix-flavored, philosophy-shaped, and operationally useless. The version that compounds is sharper: talent density is the percentage of your team performing above the median you would accept today, if you were rebuilding the team from scratch. That framing puts the median, not the headcount, at the center of every hiring decision.
Why does that distinction matter? Because the philosophy version lets you talk about "raising the bar" without ever specifying whose bar, for which role, calibrated to what current standard. The operating version forces a decision before every offer: is this person above the line our current team is holding, not above the line we set when we wrote the job spec eight months ago. Markets move. The bar moves with them, or your talent density quietly erodes.
The operational test for whether your team is actually running on talent density: ask three interviewers from your last debrief to write down, separately, what "exceeds expectations on this competency" looked like in that interview. If the three answers don't roughly match, you don't have a bar. You have a vibe.
The 2026 hiring data backs this up. According to Metaview's 2026 AI & Hiring Alignment Report - surveying 505 recruiting leaders and hiring managers across North America and EMEA - the gap between teams with high partnership alignment and teams without one shows up everywhere downstream of the interview.
My mantra has always been: I'd like to be around super high-talent-dense, high-bar environments. Sometimes that's terrifying because I have imposter syndrome. But a narrative my dad baked into me: listen, we're not always gonna be the smartest in the room, and that's the point.”
The four reasons talent density is a measurement problem
If talent density were truly a philosophy problem, every team that agreed with the idea would already have it. They don't. They have intent, debate, and an inconsistent record on the actual hires. The operating gap shows up in four specific places.
1. Performance reviews lag the hire by 6 to 12 months
By the time you know whether a hire landed above or below your median, you have already made the next 4 to 20 hires using the same calibration you used for them. The feedback loop is too slow to actually adjust the bar before the next decision. Most teams are running on a hiring model they have not validated against outcomes for at least a year.
2. Interview notes are noisier than perf data and they don't aggregate
Even teams that take careful notes are sitting on a corpus that's structurally hard to learn from. Ten interviewers writing in ten different formats, in ten different docs, with ten different definitions of "strong on system design." You can't query it, you can't compare across roles, and you can't pull out the patterns the top performers shared. The signal is there, but the data layer that would turn it into a bar is missing.
3. The "bar" is held in 12 interviewers' heads, not in a system
Each interviewer carries a personal model of what "exceeds" looks like. Some are tighter than the team median, some looser. Without a shared, instrumented anchor, the offer decision is a vote on whose personal bar is currently loudest in the debrief. New hires shift the distribution again. Three quarters in, the bar has wandered, and nobody can point to when.
4. You cannot query an instinct
The crisp version: if you can't search your interview history for "every candidate who got exceeds on commercial judgment in the last 90 days," you are not running on talent density. You are running on selective memory. The whole game is moving the signal out of the individual interviewer's head and into a layer the team can re-query as the bar evolves.
The six instrumented hiring moves that compound the bar
If talent density is a measurement problem, the cure is a measurement system. Six moves, each one anchored to a specific point in the interview flow, and each one designed to produce evidence the next hire's calibration can be checked against.
3.1 Codify the bar before you debate it
Every role needs a rubric that names the 4 to 6 competencies the bar actually runs on, with explicit anchors for what meets versus exceeds looks like. Anchor each level to a behavior you have actually seen from a current team member, not an abstraction. If you can't name the behavior, the level isn't operational. Interview scorecards are the lightest version of this layer.
3.2 Treat each interview as a data point, not a one-off conversation
Every interview should generate three artifacts: structured notes tied to the rubric anchors, a per-competency score, and a why sentence per score that another interviewer could challenge. Two of those three are usually missing. The fix isn't more discipline; it's a capture layer that produces all three by default.
3.3 Calibrate quarterly against your actual top performers, not the legacy rubric
The rubric you wrote 18 months ago is calibrated to the team you had 18 months ago. Every quarter, pull the interviews of your last 5 to 10 exceeds hires, re-read them as a group, and update the rubric anchors against what those hires actually demonstrated. This is the loop that keeps the bar honest as the team grows. Talent calibration is the discipline that turns rubrics from wallpaper into operating spec.
3.4 Raise the bar one anchor at a time
Don't rewrite the whole rubric mid-cycle. Pick the one competency where the current bar is most clearly soft, raise the anchor by one level, and run it for a quarter. Then re-check the offer-acceptance and pass-through rates. A bar that moves on one anchor at a time is auditable. A bar that moves on five anchors at once is just a reshuffle nobody can grade.
3.5 Run a hiring-bar audit every 30 days
Pull the last 30 days of interviews for one role family. Read the notes for the 5 strongest strong yes decisions and the 5 weakest. Look for two things: (a) interviewers who consistently rate tighter or looser than the median (calibration drift), and (b) competencies where the score-to-prose alignment is poor (the exceeds with no evidence). Both are leaks in your TD layer.
3.6 Close the loop from interview signal to performance review
The interview rubric and the perf-review rubric should share vocabulary. When the engineering manager says at 6-month review that this person is below bar on architectural judgment, you should be able to pull the interview signal on that exact competency in 10 seconds. Most teams can't, because the two systems were never wired together. That handoff is where the bar actually compounds.
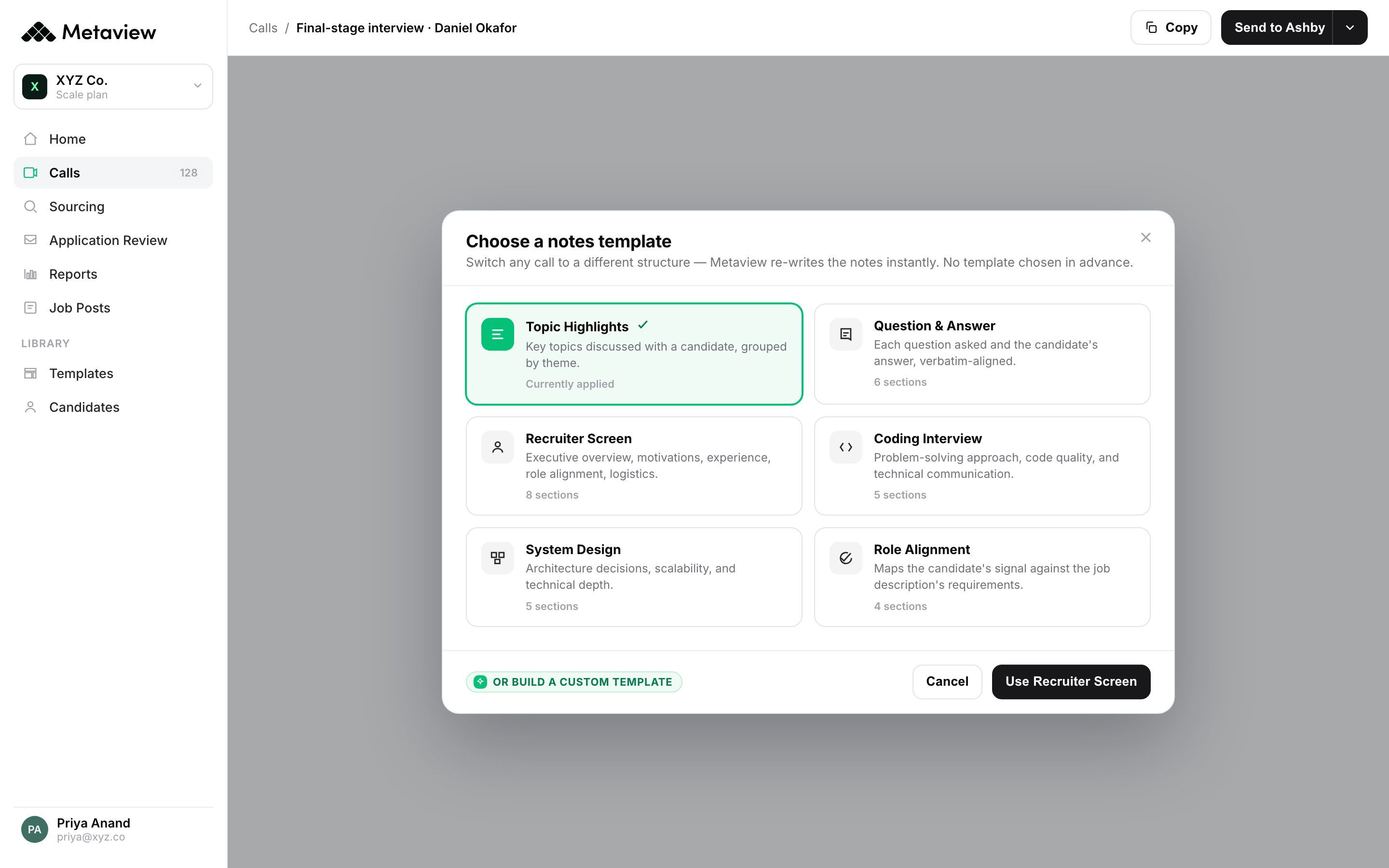
How Metaview turns each interview into evidence the system can learn from
The capture layer is where the operating model lives or dies. Manual note-taking can hit two of the three artifacts the rubric needs, but rarely all three, and never at the volume that lets you query the history later. Generic AI notetakers solve the speed problem and create a new one: notes that have no relationship to your rubric, no competency scoring, and no comparability across interviewers. The table shows the operational difference at each layer of the TD stack.
| Layer of the TD stack | Manual | Generic AI notetaker | Metaview |
|---|---|---|---|
| Capture every interview | Inconsistent; depends on interviewer discipline | Yes, raw transcript | Yes, transcript plus structured notes tied to your rubric |
| Anchor to your rubric | If the interviewer remembered the rubric | No | Notes auto-organized under your competency anchors |
| Comparable signal across interviewers | No, every interviewer in their own format | Partial, summary-shaped | Yes, scorecards in a shared shape regardless of who ran the panel |
| Searchable signal across roles | No | Free-text search at best | AI Filters: query the whole library in natural language |
| Calibration data the team can re-read | Lives in a Notion doc; rarely re-opened | Lives in scattered summaries | Per-interviewer and per-competency dashboards |
| ATS and perf-system handoff | Re-typed into the ATS, decoupled from perf | PDF dump | Native ATS sync; vocabulary shared with perf review |
What changes in 90 days when interview-data is your TD layer
The first 90 days of running interview-data as the TD layer aren't about new hires landing differently. It's too early for that. What you'll feel first is the debrief getting faster and the calibration argument getting shorter. When everyone's looking at the same structured score against the same rubric anchor, the conversation moves from did we like them to here's where I scored them a 3 and here's why. That alone shifts where the bar actually lands.
The second-order effect is the audit muscle. By month two you can pull the 30 most recent interviews for a role family and see, in minutes, which interviewers are pulling the bar in which direction. That used to be a quarterly recalibration session that nobody had time to run. Now it's a Tuesday.
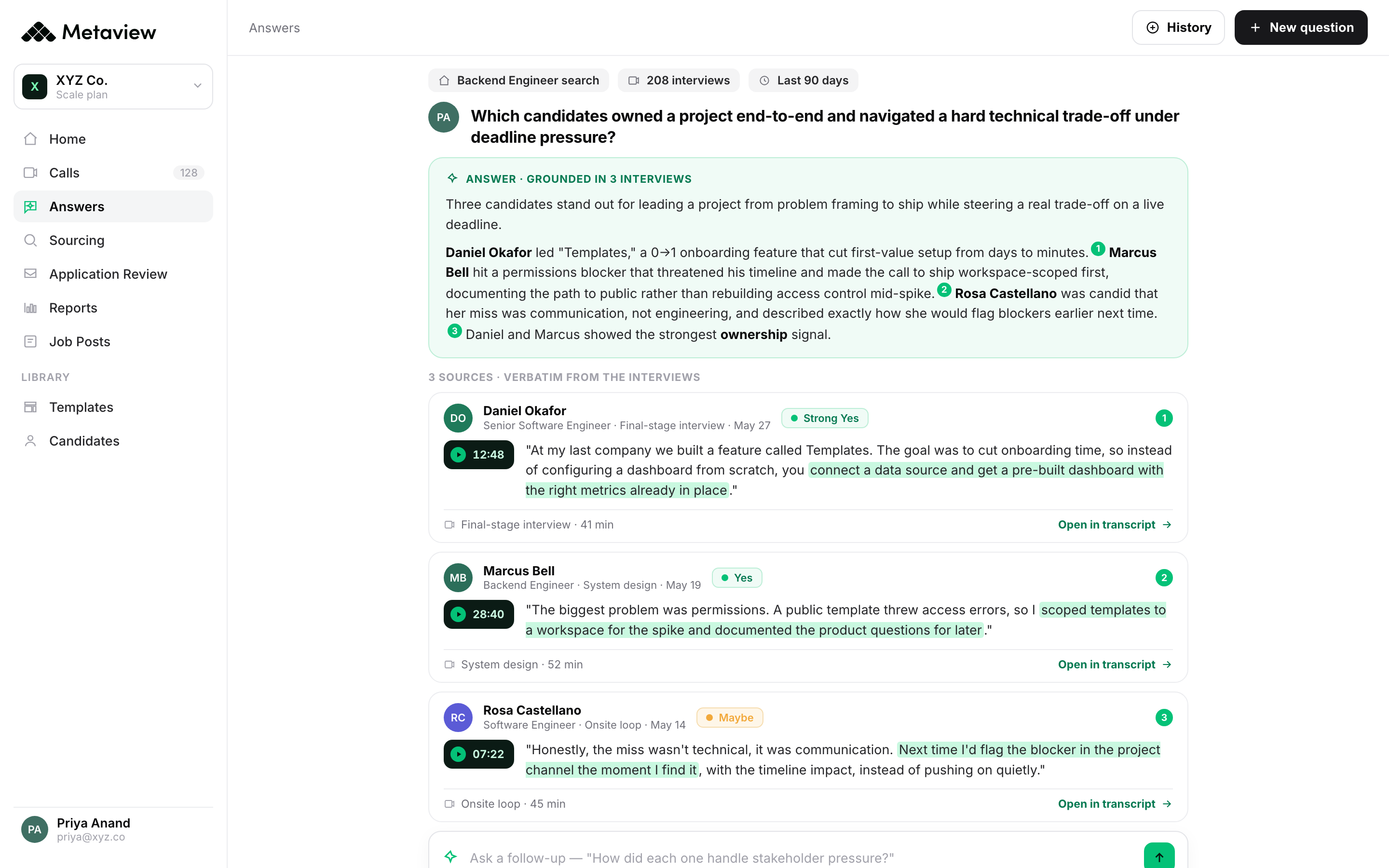
And by month three, the loop with the performance-review system starts firing. When a hiring manager flags a new hire as below bar on a specific competency at 90 days, the recruiter can pull the interview signal on that exact competency in one query. Sometimes the signal was there and got overweighted; sometimes it wasn't and the rubric needs an anchor update. Either way, the bar gets sharper for the next hire. Thach Nguyen has talked about this kind of operating model at length on the Metaview podcast:
Using Metaview Reports, we could analyze those interviews at scale instead of treating them as isolated stories. Now that we have this framework, the goal is to expand it beyond the Golden Circle. Who are our top leaders and top performers in Engineering, Product, or Marketing?”
Meltwater's Senior Director of Global Talent, Carol Ann Vance, interviewed four years' worth of the company's top sellers - the Golden Circle, Meltwater's president's-club tier - then used Metaview Reports to extract the consistent themes across 40+ conversations. That's a literal talent-density playbook: identify the median you'd accept today, codify the behaviors that put your current top performers above it, and run every new interview against those anchors. The framework now extends from go-to-market into Engineering, Product, and Marketing.
 Metaview
MetaviewA 30-day talent-density audit
Don't wait for the next perf cycle to find out whether your bar is drifting. The audit below runs in 30 days, doesn't require a tooling change to start, and surfaces exactly where your TD layer is leaking.
- Week 1 - Pull the receipts. Export every interview from the last 30 days for the chosen role family. Note who interviewed, the rubric they were scoring against, and the score they gave per competency. If any of those three is missing, that's the leak.
- Week 2 - Read the 5 strongest and 5 weakest hire decisions. Look for score-to-prose alignment. An exceeds with no concrete behavior named in the notes is a calibration ghost. Tally them.
- Week 3 - Run the calibration drift check. Per interviewer, compute the average score they gave vs. the team median for the same role and competency. Anyone more than 0.5 points off needs a calibration session before their next interview.
- Week 4 - Update one rubric anchor. Pick the competency where calibration ghosts are most concentrated. Rewrite the exceeds anchor to name a behavior an actual current top performer demonstrated. Ship it. Track offer-acceptance and 6-month perf for hires made against the new anchor.
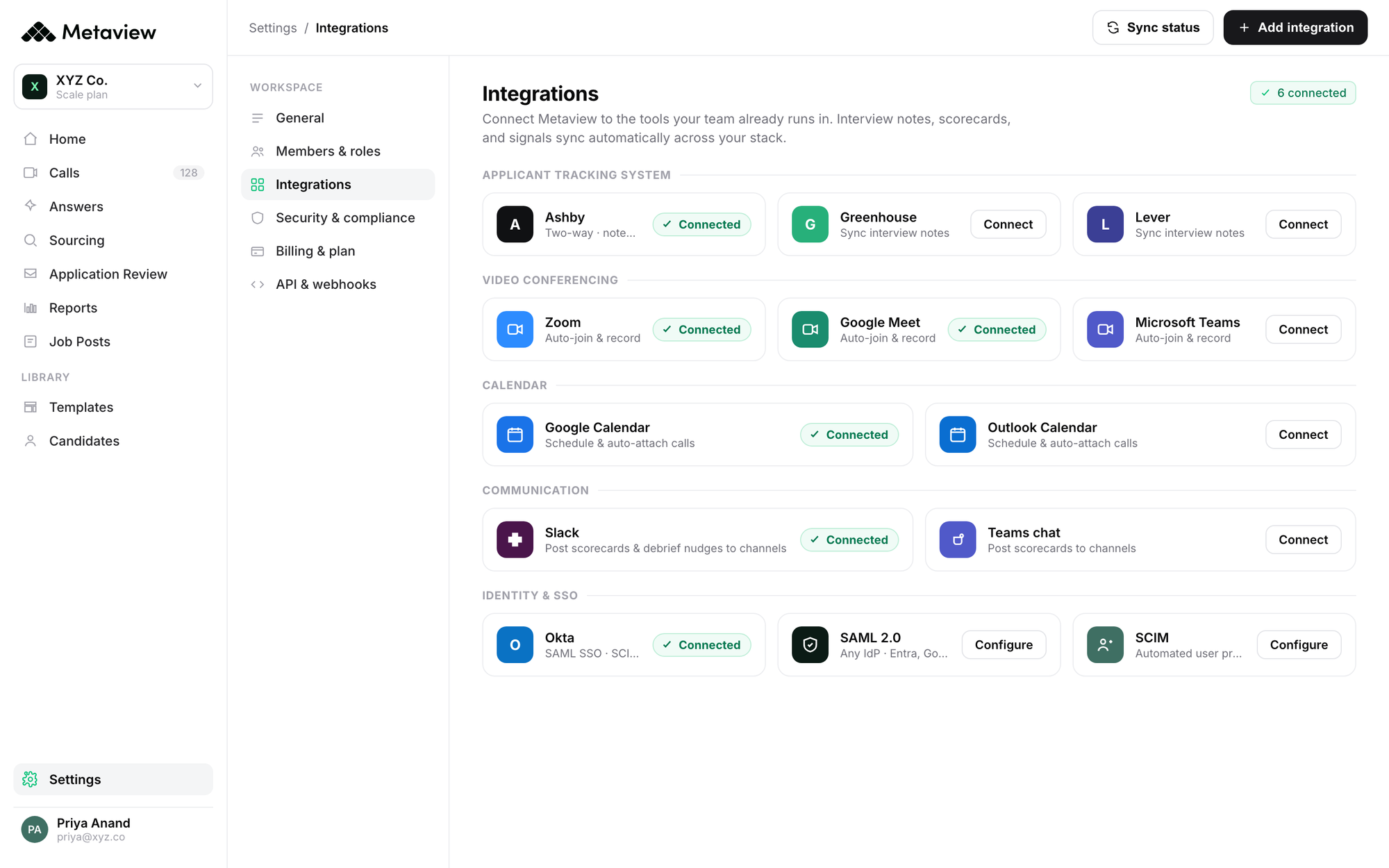
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Frequently asked questions
What is talent density?
Talent density is the percentage of your team performing above the median you would accept today if you were rebuilding the team from scratch. The key word is today: as the team grows and the market shifts, the median moves, and your hiring bar has to move with it.
How do you measure talent density without waiting for the next perf cycle?
By instrumenting the interview, not the perf review. Score each interview against a rubric anchored to current top-performer behaviors. Then run a 30-day audit on a single role family: calibration drift per interviewer, score-to-prose alignment per competency, and offer-acceptance against the rubric's current anchors. That gives you a leading indicator the perf-cycle telemetry can't.
Why is talent density a measurement problem, not a philosophy problem?
Because the philosophy version is universally agreed upon and the operating results vary wildly. Every team says they want to raise the bar. What separates the teams that compound from the teams that drift is whether the bar lives in a system the team can re-query, or in 12 interviewers' heads that quietly disagree.
Does raising talent density mean lowering hiring volume?
No. The trade-off is volume of noisy hiring vs. signal density per interview. Teams that raise TD don't run fewer interviews; they run interviews that produce structured, comparable, queryable evidence. The candidate experience often improves because the panel is asking sharper questions against a clearer anchor.
How long does it take to see talent density actually move?
Calibration tightening starts shifting debrief behavior in the first 30 days. Bar drift becomes visible in the audit by month two. New-hire perf outcomes against an updated rubric anchor take a full 6-month cycle to confirm. Teams that wait for the perf-cycle confirmation before updating the rubric never close the loop.