

Three weeks into a search, the shortlist is bloated and the hiring manager still says "this isn't quite right." Most recruiters interpret that as a sourcing problem and respond by searching harder. It's the wrong fix.
Quality isn't decided at the top of the funnel. It's decided at the intake call, when the rubric gets locked or doesn't. Everything downstream just expresses what happened in that hour.
This post walks the loop end to end: calibration captured at intake, interview signal carried through to the shortlist. Five moves a recruiter at her desk can run, with the Metaview surfaces that make each one stick.
Why calibration is the upstream lever
Most "low-quality candidates" are high-quality candidates evaluated against an unclear bar. The bar lives in the hiring manager's head; the recruiter is guessing at it from the JD; the interviewer is interpreting it from a 20-minute kickoff call three weeks ago. By the time anyone scores a candidate against the rubric, three different rubrics are in the room.
That's a calibration problem dressed up as a sourcing problem.
The in-interview signal is where the rubric gets tested. A strong candidate on paper falls apart in a structured competency conversation; a borderline resume reveals deep ownership patterns once you ask the right follow-ups. Calibrate before the search runs, and every downstream conversation has a stable bar to test against.
That gap shows up everywhere downstream. Teams that lock the rubric at intake hit faster cycle times, fewer mismatched profiles, and a hiring manager who trusts the shortlist. Teams that don't run every search asking the same question recruiters have been asking forever: "we keep seeing the wrong people; why?"
What quality at scale looks like in practice
The five moves below are sequenced for the recruiter who runs the workflow. Each one is a Friday-by-Friday discipline, not a strategic overhaul. Discipline matters from step one; the product layer matters at steps three through five.
1. Calibrate before the search runs
The intake call is where quality is decided, weeks before any candidate hits the funnel. Most teams treat it as a JD briefing. The strong recruiters treat it as a rubric session: what does excellent look like, what does adequate look like, what does the wrong-fit-but-impressive resume look like?
Push the hiring manager past the responsibilities and into the success outcomes. "What would this person have shipped by month six?" produces a sharper rubric than "what skills do they need on day one?" The intake call earns the search, or it doesn't.
2. Name the competencies, not the role
Competency-anchored JDs filter the funnel before it fills. Generic "5+ years of relevant experience" pulls in everyone; "ownership of cross-functional pricing decisions in a high-growth SaaS environment" pulls in the right five. The competencies came from the intake call; the JD puts them in front of candidates and self-selects the funnel. The same rubric carries forward into Application Review so the inbound triage uses the bar the team agreed on.
This is also where bias gets anchored to observable signal instead of subjective preference. The next interviewer in the chain is scoring against the same competency frame the JD advertised, not their own gut take on the resume.
3. Score in the call, not after
Post-call scoring is where the rubric drifts. Memory fades by the next interview; the candidate's strongest answer blurs into the candidate's strongest objection. The fix is scoring as the candidate finishes a response, not after the call wraps.
That requires the rubric open in front of you, the questions sequenced to map onto it, and the discipline to write a number while the voice is fresh. Recruiters who score in the call surface signal their post-call colleagues never see.
4. Capture every interview as structured data
This is the move that compounds. Unstructured notes lose 80% of the conversation; structured capture turns every screen into a piece of the candidate record that the next interviewer, the hiring manager, and the next search can all read. AI Notes does the work. The recruiter pays attention to the candidate, the structured note lands in the post-meeting view, and the scorecard auto-populates against the rubric.
The capture surface is the data layer that every downstream decision sits on. Without it, the scorecard is a memory exercise. With it, the scorecard is a record.
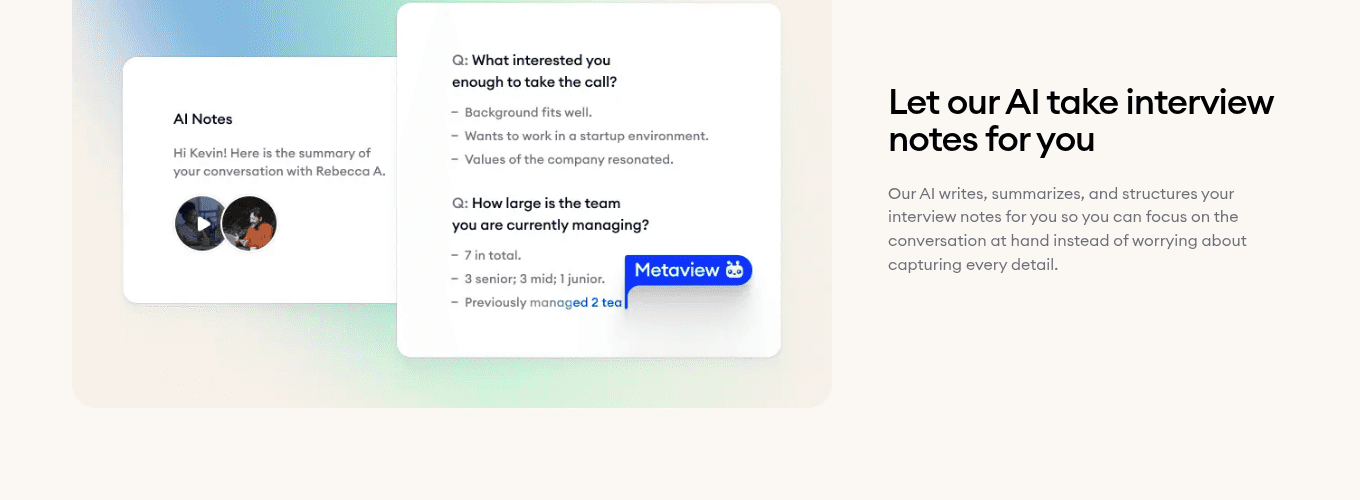
- 1Structured Q and A pairs landed against the competency rubric the team agreed at intake.
- 2Topic chips tag every signal so the rubric scoring is searchable by competency, not by candidate name.
- 3Recording controls let the recruiter jump back to the exact moment a competency landed in the conversation.
5. Compare against the rubric, not each other
Candidate-vs-candidate framing is where interviewer bias creeps back in. The strongest candidate in the room becomes the bar; everyone else gets scored against them instead of the rubric. The fix is rubric-anchored framing. Every candidate's score is read against the 1-3-5 the team committed to at intake.
The shortlist becomes a rank-against-the-bar exercise, not a beauty contest. Reports surfaces the cross-candidate view so the recruiter can see who clears the bar on which competencies, with the supporting evidence pulled from the structured notes.
Why structured capture beats screening harder
The volume premise says more candidates equal more signal. The capture premise says better signal equals fewer candidates. The five moves above only work if the capture system holds. Without it, the rubric drifts, the notes fade, and every search starts cold. With it, capture compounds across searches: the rubric inherits, the scorecards stack, the next intake call starts from real evidence.
- Manual notes drift by Friday, signal lost.
- Scorecards filled days late, against fading memory.
- Bias creeps in via candidate-vs-candidate framing.
- Every search starts cold, no inherited rubric.
- Shortlist signal lives in the recruiter's head.
- Notes structured at the moment of the call.
- Scorecards auto-populated against the rubric.
- Rubric-anchored framing holds the bar steady.
- The rubric inherits search to search.
- Shortlist signal is a system output.
The reader who has felt the manual side knows this immediately. Notes from a Tuesday screen are useless by Thursday's debrief; the scorecard becomes a polite reconstruction of what the interviewer remembers feeling, not what the candidate said. The capture system removes the memory tax. The signal stays where the candidate left it.
How Metaview turns calibration into shortlist signal
The chain runs from the intake call through the shortlist, with each surface holding the rubric the previous one set.
AI Sourcing pulls profiles against the calibrated rubric, not a keyword string. AI Notes captures every conversation against that same rubric. Reports surfaces the cross-candidate view, so the shortlist is a rank-against-the-rubric output rather than a recruiter intuition.
The whole loop runs on top of native ATS integrations, so the structured signal lands back in the system of record the team already uses.
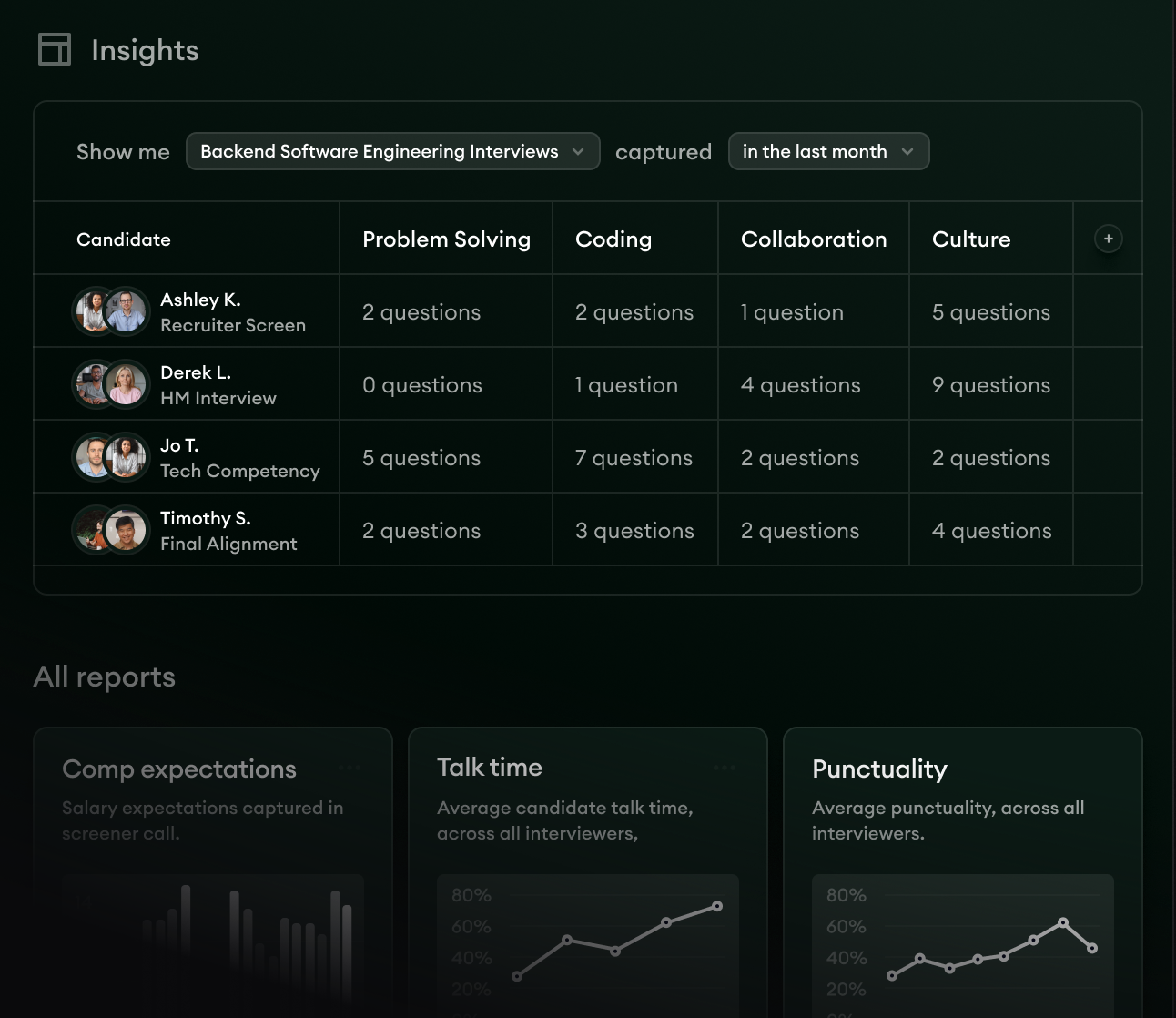
- 1Per-competency rows mirror the rubric the team locked at intake.
- 2Supporting evidence pulls from the structured notes, so every score traces back to a real moment in the conversation.
- 3Cross-candidate ranking surfaces who clears the bar on which competencies, not who beats whom.
The shortlist becomes a system output rather than a judgment call. Data holds the candidates; the recruiter holds the relationships. Her time spends on candidate experience, hiring manager partnership, and the high-leverage conversations the rubric flagged. Not on the spreadsheet that used to live everywhere and nowhere.
With Metaview's analytics, we've really elevated the way we guide clients with evidence-based insights, rather than gut feel. We're creating a faster, clearer and more data-driven experience for everyone involved.”
Build A+ shortlists at scale
Quality candidates don't emerge from bloated pipelines. They emerge from the loop: calibration at intake, competency-anchored JDs, scoring in the call, structured capture across every conversation, and rubric-anchored shortlist decisions. Shortlists become a system output when the loop holds; they stay a judgment call when any link breaks.
The recruiter who runs the loop hits faster cycle times, sharper hiring manager partnerships, and a quality signal that survives Friday. The team that runs the loop turns each search into an asset the next search inherits. That's quality at scale.
Frequently asked
How early can you measure candidate quality?
At three concrete stages, each earlier than recruiters usually think. The intake call gives you the rubric and the must-haves; the application review triage gives you the resume-against-competency match; the first conversation gives you the rubric-against-evidence score. Quality at scale comes from instrumenting all three, not from waiting for the final round to make the call.
What's the difference between candidate quality and quality of hire?
Candidate quality is the pre-hire predictive signal: how well the rubric scores the candidate against the role's competencies before the offer goes out. Quality of hire is the post-hire outcome: how the person performs at month six, month twelve, and beyond. The two are orthogonal but related: a strong candidate-quality signal feeds quality of hire, but the measurement happens at different points in the lifecycle. The longer playbook on the post-hire side lives in our quality of hire post.
Can AI evaluate candidate quality without introducing bias?
AI evaluates against the rubric the humans set. The bias mitigation lives in the rubric discipline (clear competencies, observable signals, written 1-3-5 scoring guides), not in the AI tool itself. The system extracts signal against the bar the team agreed on; if the bar is well-calibrated, the AI removes the recruiter-memory drift and the candidate-vs-candidate framing that introduce the most common bias patterns.
What if my hiring manager won't commit to calibration?
Build the rubric backward. Structured capture means every interview surfaces the evidence the rubric should have asked for; by the second or third hire, the hiring manager has the framework in evidence even if the intake call was vague. The conversation shifts from "what are you looking for?" to "look at the last three hires: what worked, what didn't, what does the next rubric need?"
Does Metaview replace human recruiter judgment?
No. The structured capture removes the administrative work that used to consume the recruiter's day (note-taking, scorecard reconstruction, candidate spreadsheet maintenance) so the judgment work gets the recruiter's full attention. The high-leverage work is relationship building with the candidate, partnership with the hiring manager, and the rubric judgment calls the system flags. The system holds the data; the recruiter holds the decisions.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.