

Open five buying guides for interview intelligence software and you'll read the same page five times. A grid of checkmarks, a row for transcription, a row for summaries, a row for ATS sync, and a verdict that crowns whichever tool filled the most rows. None of it answers the one thing you actually need to know, which is what happens when this thing sits in your real interviews.
So here's a different way to buy. Don't shortlist on features. Pick three or four contenders, run each of them on the same set of interviews you've already done, and read the output side by side. The grid measures what a vendor decided to build. The output measures whether a hiring manager would trust the result. Those are not the same test, and only one of them predicts whether you'll still be using the tool in a year.
What makes this matter more in 2026 than it did in 2022 is that the category quietly split in two. On one side, single-point notetakers that turn an interview into text. On the other, recruiting workflows where the interview is one input into sourcing, screening, scorecards, and reporting that all talk to each other. They demo almost identically. They are not the same purchase. The cheapest way to tell which one you're looking at is to ask what it does after the transcript is written. If the answer is nothing, you bought a very expensive tape recorder.
Why the feature grid is the wrong test
A feature grid feels objective because it's a table. It isn't. Someone chose which rows go in it, and every vendor on the list optimized for those rows. So the grid rewards whoever has the longest changelog, not whoever produces the most useful read on a candidate. You end up comparing marketing surface area, then acting surprised when the tool that won the grid underwhelms in week three.
Features rarely survive contact with a real interview. Two tools can both claim AI summaries and produce wildly different things. One gives you a tidy paragraph that reads well and says nothing. The other pulls the exact follow-up the candidate fumbled and ties it to the competency you were testing. The grid scores both as a single checkmark and moves on.
There's also a category problem hiding inside the grid. A lot of the tools on a typical interview intelligence list are general meeting notetakers that happen to work on a hiring call. The rest are built for recruiting, where the interview is wired into the rest of the funnel. The grid flattens that into a transcription row, when that gap is exactly what determines whether the tool is useful to a talent team. It's the whole game, and I'll come back to it.
The fix isn't a better grid. It's a better test, and it's one you can run this week with interviews you've already recorded.
The one test that matters: run it on your interviews
Here's the test I'd run before signing anything. Pick the tools you're seriously considering. Take five real interviews from a role you actually hired for, with a mix in there: a screen, a couple of panels, one where the decision was close. Run every tool on the same five. Then put the outputs next to each other and ask one question of each: would the hiring manager make a call from this, without re-watching the interview?
That question sounds soft. It's the entire job. The point of interview intelligence isn't notes for their own sake, it's a record a hiring team will trust and act on. If the output is a clean transcript nobody opens, you've automated note-taking and changed nothing about the decision. If it's a structured, sourced read a hiring manager picks up and runs with, you've changed the decision itself.
This is a problem people have been circling for a long time. We've spent more than five years on how you turn what's said in an interview into something a team can use, and the honest summary is that the transcript was never the hard part.
When the output is genuinely good, you can feel the debrief change. A recruiter stops bringing opinions to the table and starts bringing evidence.
Hiring managers want to see data, not feelings. When you can say ‘75% of candidates in this market expect remote work’ and back it up with real conversation data, it changes the conversation.”
What to actually test
Once the outputs are side by side, you're really testing for behaviors, not feature names. The tools that earn their place do a handful of things a transcription service can't, and the gap shows up fast when you read real interviews instead of a demo script.
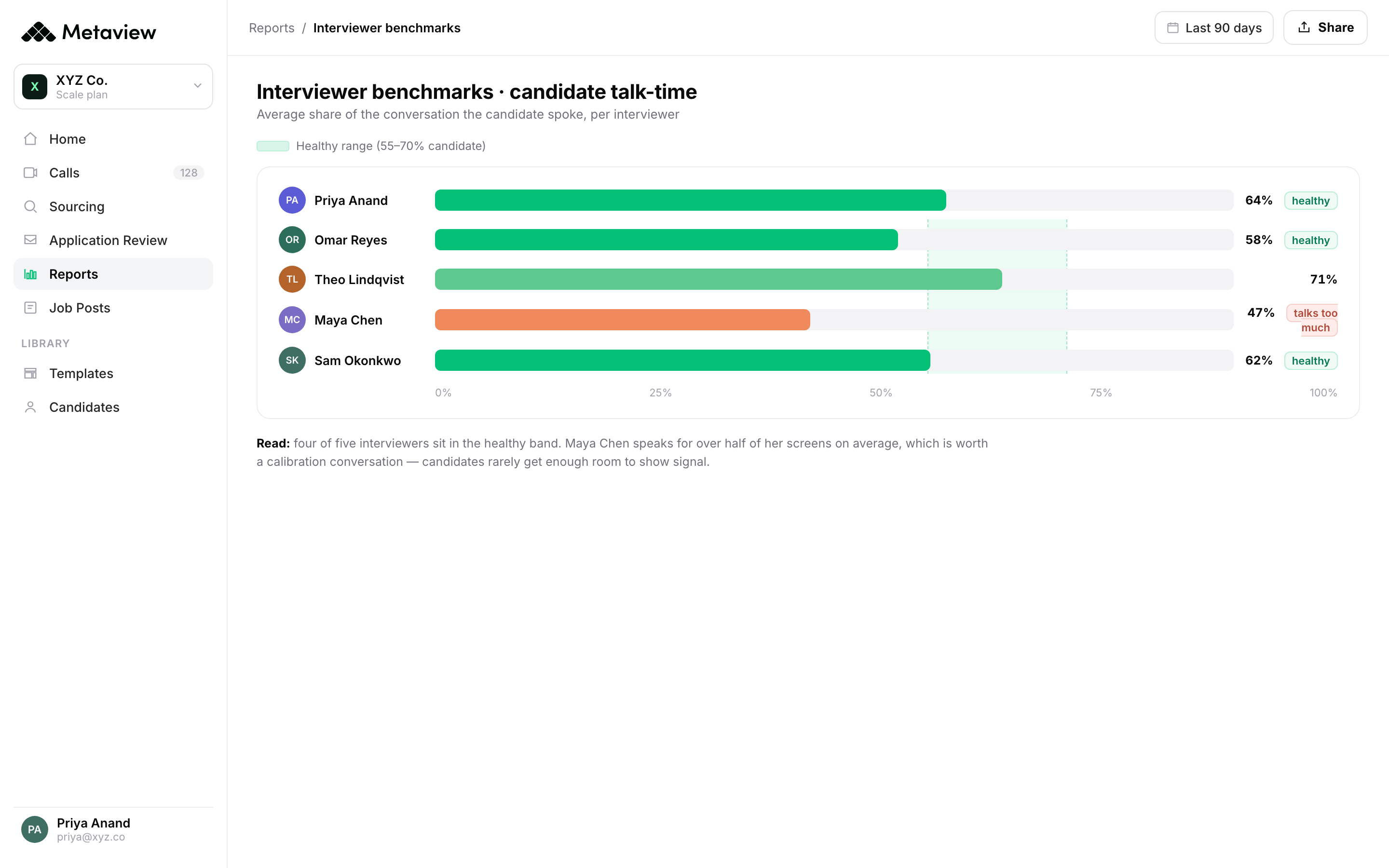
Start with retrieval. Ask each tool to find the exact moment a candidate talked about a hard tradeoff, or every place across your pipeline where someone mentioned a competing offer. A notetaker hands you a transcript to scroll. Real interview intelligence hands you the line, with the context around it. Reports is where that lives for us: you ask in plain language and the answer comes back from every conversation, not one.
Then test whether it can look at the interviewer, not just the candidate. An honest read on a hiring process includes whether the panel actually assessed what they meant to, or whether one interviewer talked for forty minutes and called it a signal. A transcript can't tell you that. A benchmark across your interviews can.
Put the two camps next to each other and the test gets easy. You're not scoring features, you're scoring what the tool does with the interview once it's over.
- Turns the interview into a transcript and a summary, then stops
- Lives in its own tab, disconnected from sourcing and your ATS
- Treats every meeting the same, with no view across the pipeline
- Surfaces the specific moment and ties it to the competency you tested
- Feeds the same record into screening, scorecards, and reporting
- Benchmarks interviewers and trends across every conversation you run
Why a workflow beats a single-point tool
Run the bake-off across enough roles and a pattern shows up. The tool that wins isn't the one with the prettiest summary. It's the one that does something with the interview after it's over. That's the line between a point tool and a workflow, and it's the line that tracks with results.
It isn't only my read. According to Metaview's 2026 AI & Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, 85% of companies that exceed their hiring goals use AI in hiring. The same report is blunt about how they use it. The teams seeing the best results build shared systems that work from one source of truth. The teams seeing the worst results buy individual copilots that make each person a little faster in isolation. A single-point notetaker is the second thing wearing the clothes of the first.
When the interview is wired into the rest of hiring, the record stops being a document and starts being infrastructure. The same captured conversation that writes the notes also fills the scorecard, screens the inbound through Application Review, and tells your next search what good sounded like. A notetaker can't do any of that, because it threw the structure away the moment it emailed you a summary.
Teams that buy the workflow describe it the same way, and they rarely lead with the transcript.
We've completed over 1,900 calls using this platform, saving 77 full workdays. We're not just automating note-taking, we use the multi-source feature so each interviewer goes in unbiased but informed enough to cover new ground.”
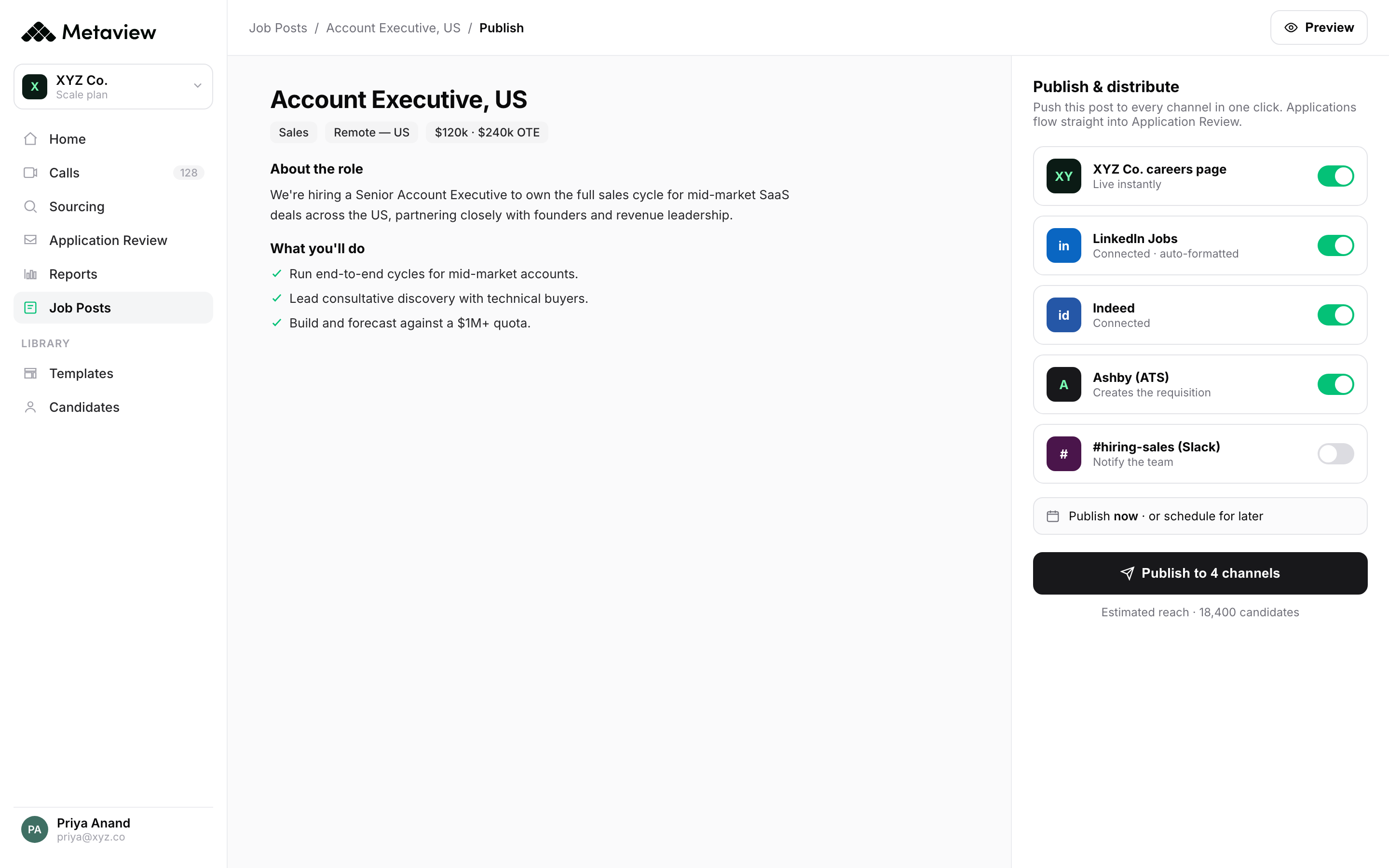
And because it's one platform, the same context shows up in places a notetaker never reaches, like drafting and publishing the job post for the next opening off the role you just defined.
Get the evaluation checklist
The full version of this test as a printable scorecard. Start free, then run it against Metaview and anything else you're weighing.
Start free. No credit card.
What this changes for how you buy
If you lead a talent team, this buying decision is really an architecture decision, and it outlives the tool. Pick a notetaker and you've added a feature. Pick a workflow and you've changed where your hiring knowledge lives. So the last things to test are the ones that don't demo well but matter for years.
Ask where your interview data sits, who can see it, and what happens to it when you leave. Interview recordings and transcripts are some of the most sensitive data a company holds, and a tool that's casual about that is a liability no summary quality makes up for. Check the controls before you fall in love with the features.
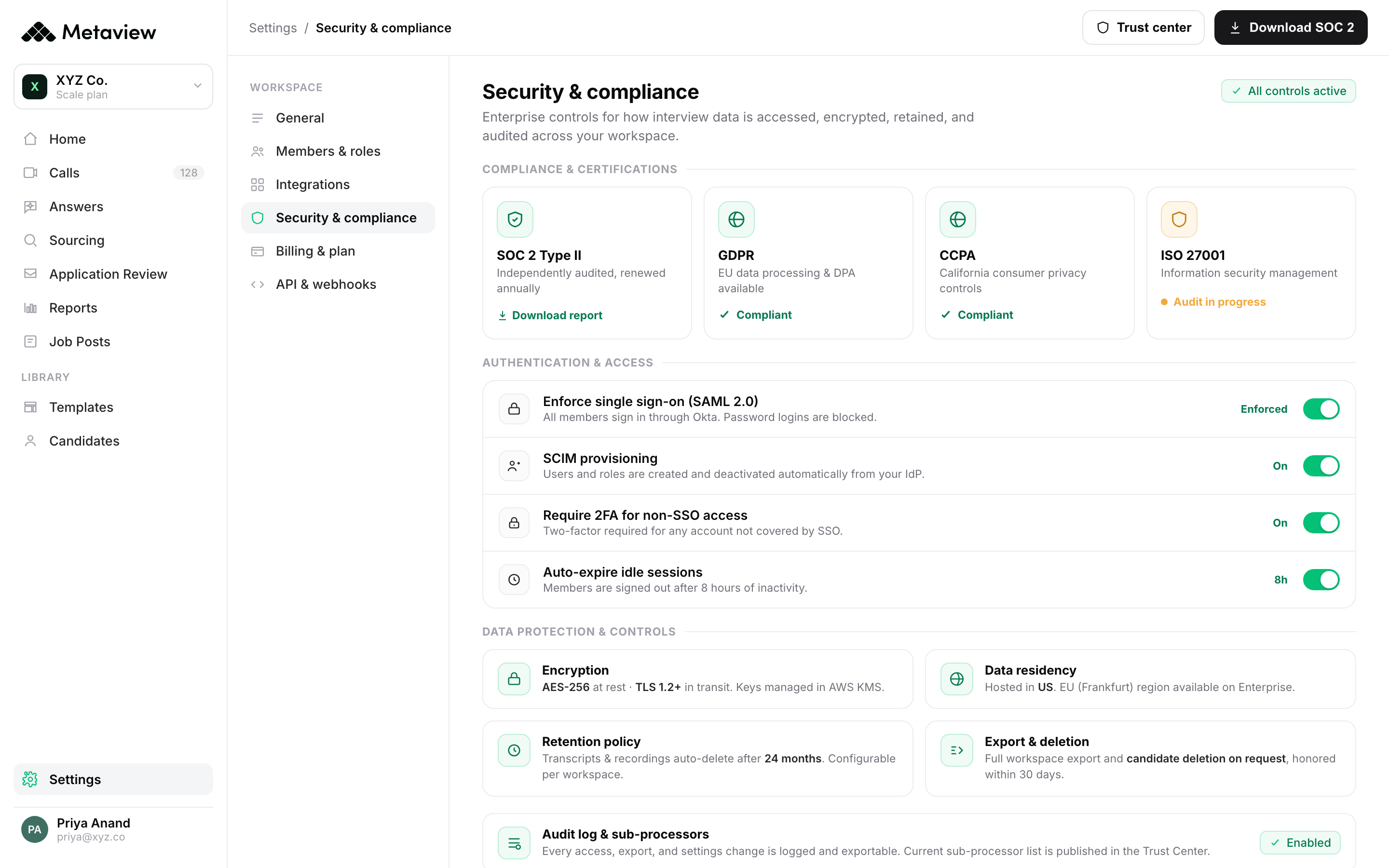
Then ask the question that separates a workflow from a toy: does it get better as you hire? The systems worth buying compound. Because the Notetaker captures every spoken word in every interview, the record is the real thing that was said, not a form someone half-filled afterward, and every hire it sees makes the next read sharper. Connect it to your stack through native integrations and that context follows the candidate instead of dying in a tab.
If you want the wider argument for why this is where recruiting is heading, this conversation gets into it.
You don't have to rip out what you've got to run the test. Put Metaview next to your current tool, give both the sourcing and screening context, run the same interviews through each, and see which one a hiring manager actually trusts. You can check what it costs on pricing, and see how other teams made the call.
Compare the output, not the feature grid.
Put Metaview next to whatever you're evaluating, give it your real interviews, and see which one produces a read a hiring manager will actually act on.
Frequently asked questions
What is interview intelligence software?
Interview intelligence software captures what's said in interviews and turns it into structured, searchable signal a hiring team can act on: notes, summaries, scorecards, interviewer benchmarks, and trends across the pipeline. The strongest tools go past transcription and wire the interview into sourcing, screening, and reporting, so the record improves the hiring decision rather than just saving note-taking time.
How do I evaluate interview intelligence tools?
Skip the feature grid and run a bake-off. Take five real interviews you've already done, run each tool on the same five, and compare the actual output. For each one, ask whether a hiring manager would make a call from it without re-watching the interview. Then test the things that don't demo well: where your data lives, what it connects to, and whether it gets sharper as you hire.
What's the difference between an AI notetaker and interview intelligence?
An AI notetaker turns an interview into a transcript and a summary, then stops. Interview intelligence does something with that record afterward: it finds the exact moment that matters, benchmarks interviewers, updates a scorecard, and feeds the rest of the funnel. They look identical in a demo. The test is what happens after the transcript is written.
Is Metaview an interview intelligence tool?
Metaview is a full recruiting workflow that includes interview intelligence. The Notetaker captures every interview, Reports answers questions across every conversation, and the same record feeds Application Review, scorecards, and your ATS through native integrations. Because it's one platform rather than a single-point notetaker, the context compounds as you hire.
What should I test before buying interview intelligence software?
Test whether it can find a specific moment rather than just hand you a transcript, whether it benchmarks interviewers and not only candidates, whether it produces a scorecard a hiring manager will act on, whether it connects to your ATS and the rest of the funnel, and where your interview data lives. Score each tool zero to two and add it up.
Can I run interview intelligence alongside my current tools?
Yes. The cleanest way to evaluate it is side by side: keep your current setup, put the new tool next to it, and run the same interviews through both. With Metaview you can start free, give it real interviews, and compare the output directly before you change anything in your stack.