

Most engineering pipelines in 2026 still treat technical sourcing as a search problem. You write a Boolean string, you scrape LinkedIn or a Git host, you spray-and-pray a sequence, you measure reply rate. That mental model came out of 2015. It is not the model that wins in 2026.
The signal that actually predicts which engineer passes your bar does not live in a search filter. It lives in the conversations you have already had: the screens, the debriefs, the takeoffs, the rejections. Every interview your team has run is a labeled training example for what good looks like in your specific company, for your specific stack, with your specific hiring manager. Most sourcing stacks throw that signal away.
Cockroach Labs ran the math: 14 work weeks of recruiter time recovered once interview capture stopped being manual. That is not just a notes story. It is a sourcing story. Every captured interview becomes a calibration signal that sharpens the next outbound list, narrows the next screen, and tightens the next hiring manager debrief. In this guide, we cover what technical sourcing actually is in 2026, where the loop breaks for most teams, what AI-native sourcing looks like in practice, and the operating model that turns engineering interview signal into your sharpest outbound filter.
Technical sourcing in 2026: from Boolean strings to calibrated signal
Technical sourcing is the work of finding, evaluating, and engaging engineering candidates who do not apply through your front door. For most of the last decade, that work was a Boolean-string problem: write a smart query, filter by skills and years of experience, message everyone who matches. The query was the sourcer's primary artifact. The reply rate was the headline metric. Volume was the lever.
That model assumes the search filter is where the signal lives. It is not. In 2026, the strongest signal about which engineer passes your bar lives in the interviews you have already run. The accept/reject pattern from your last 80 phone screens is a more precise filter than any Boolean string you can write. The cross-call summaries from your hiring manager debriefs encode requirements your job description cannot articulate. The rejection reasons your team types into the ATS are labeled data.
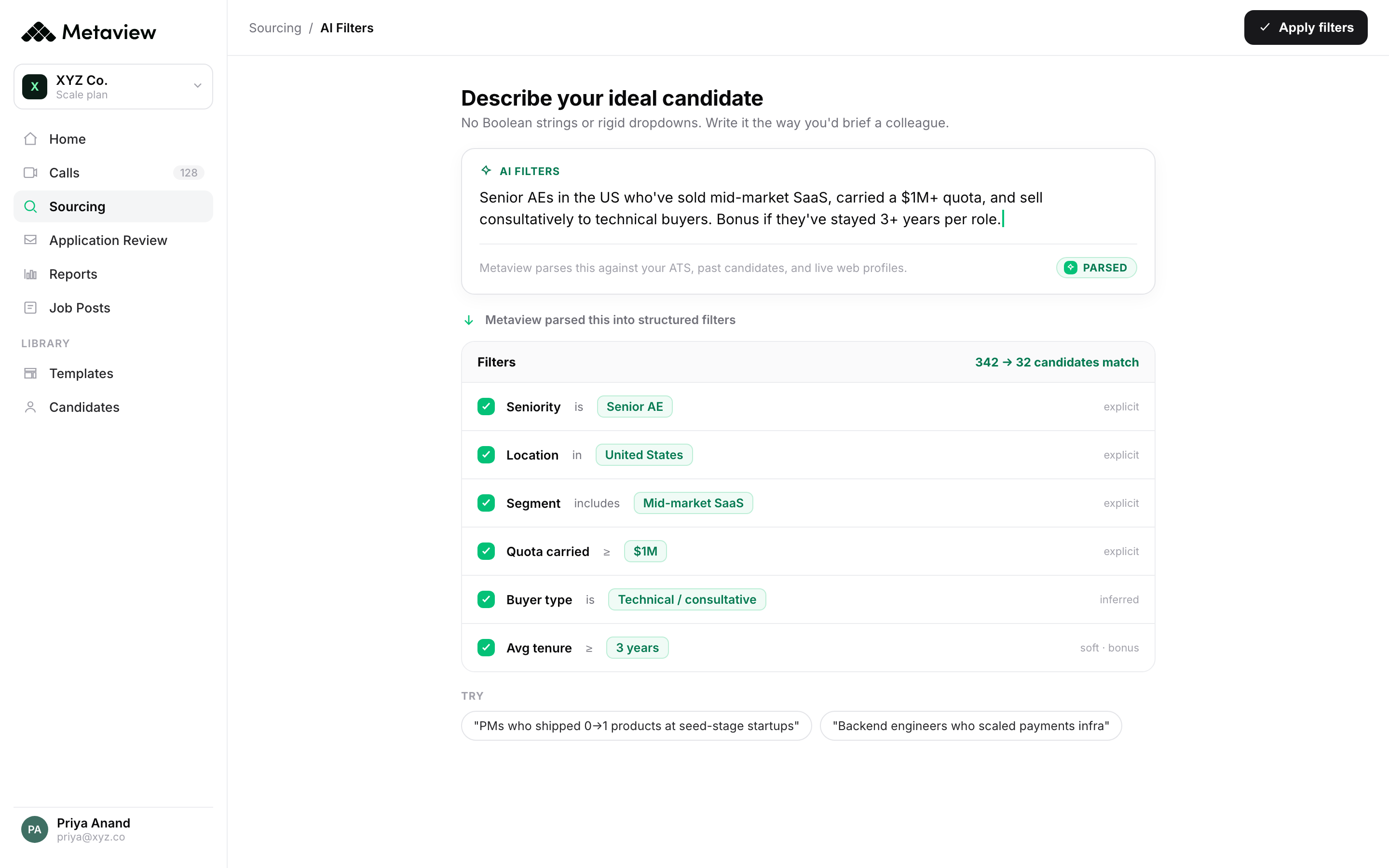
Metaview's AI Filters is a small product surface that makes this point concrete. You do not write a query string. You describe the candidate you want in natural language, and the agent runs that against your ATS, your past Metaview conversations, and external sources, all from a single prompt. The query layer becomes a calibration layer.
Why this matters now: according to Metaview's 2026 AI & Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, 85% of companies exceeding their hiring goals already use AI in hiring, and the gap between AI-native and not-AI-native sourcing programs is widening on every leading indicator the survey tracked.
What technical sourcers actually do (and where the loop breaks)
Before talking about how AI changes the role, it is worth being precise about what a technical sourcer is. A technical sourcer is a recruiter who specializes in identifying, engaging, and qualifying engineering candidates, with enough technical literacy to read GitHub repos, parse stack signals, and have a credible conversation with a passive engineer about their work. They sit between the engineering hiring manager and the recruiting funnel. Their job is to keep that funnel full of engineers who pass the bar.
The skills that actually matter
Technical literacy is table stakes. A strong technical sourcer can name the languages, frameworks, and infrastructure on a JD without prompting, and can distinguish between a senior backend engineer who has done distributed systems and one who has done CRUD apps with a database in the loop. They understand the difference between a Stack Overflow reputation built on Java answers and one built on Rust. They can read a GitHub profile and infer whether a repo is a serious commit history or a tutorial fork.
Where the loop typically breaks
The breakage is rarely on the sourcer's side. The breakage is between the sourcer and the engineering interviewer. The sourcer builds a list, runs outreach, books screens. The engineer interviewer takes the screen, decides yes or no, and the reasoning either gets typed into the ATS in two sentences or, more often, disappears into Slack DMs. That reasoning is the calibration signal. When it is not captured systematically, the next sourcing list reflects what the sourcer thinks the engineer wants, not what the engineer actually says yes to.
Why volume is not the answer
When the loop is broken, the default fix is to throw more sourcing at the problem. More sequences, more touches, more pipeline. That works until you realize the marginal sourced candidate is no better-qualified than the first. You are not running a calibrated search, you are running a wider one. Reply rate flattens. Engineer interviewer fatigue goes up. Time-to-fill stays where it is.
What changes when interview signal is captured
When every engineering interview is captured, structured, and fed back into the sourcing surface, the sourcer's primary work product shifts. The Boolean string stops being the artifact. The ideal candidate profile, refined by every accept/reject decision your team has made, becomes the artifact. The sourcer's job becomes engineering that profile and curating its evolution, not writing better filters.
For every candidate Gasper gave a strong yes, 87% ended up with the offer. Doesn't matter if it was a values or coding interview, strong yes meant offer. So I dumped all his transcripts into ChatGPT to extract the actual behaviors that distinguished strong-yes from yes from fail. Three hours of work on a Friday night.”
The 5-step technical sourcing workflow, instrumented
The classic 5-step technical sourcing workflow predates the calibration model. It still works as scaffolding, but each step has a different shape when interview signal is in the loop. Here is the version that runs in 2026.
1. Calibrate the role with the hiring manager
This is no longer a one-off intake call followed by a JD that gets forgotten. The intake conversation is captured, summarized, and stored as the seed of the ideal candidate profile. Every subsequent engineering interview the hiring manager runs adds signal back into that profile. The role does not drift from JD over a 6-week search. It sharpens.
2. Identify the talent pool
External sources still matter. So do the talent pools you already own: past applicants, silver medalists, past Metaview conversations, internal referrals. The sequence of priority flips. Owned talent pools come first because they carry the highest-quality signal: you already know how those candidates performed in an interview. External sources fill the gap after the owned pool is fully searched.
3. Search and evaluate profiles
Boolean strings still exist, but they are an output of the agent, not an input from the sourcer. The sourcer describes the target candidate in natural language. The agent constructs the query, runs it, and returns ranked candidates with reasoning attached, citing which signals from past interviews influenced the ranking. The sourcer's job is to accept or reject each candidate. Each decision feeds back into the next search.
4. Personalize outreach with verified context
Personalization is no longer 'mention their GitHub project in the first line.' It is grounded in what the agent has read across your past interviews and ATS history: who at the candidate's prior company has been interviewed before, what came up in those interviews, which competencies the candidate would be uniquely qualified to discuss. The outreach references context the candidate can verify.
5. Hand off cleanly to the recruiting funnel
Every interview the sourced candidate has, from the recruiter screen forward, is captured. The summary, the rejection reason (if rejected), and the hiring manager debrief are all written back into the ideal candidate profile. The 5th step is also the 1st step of the next search.
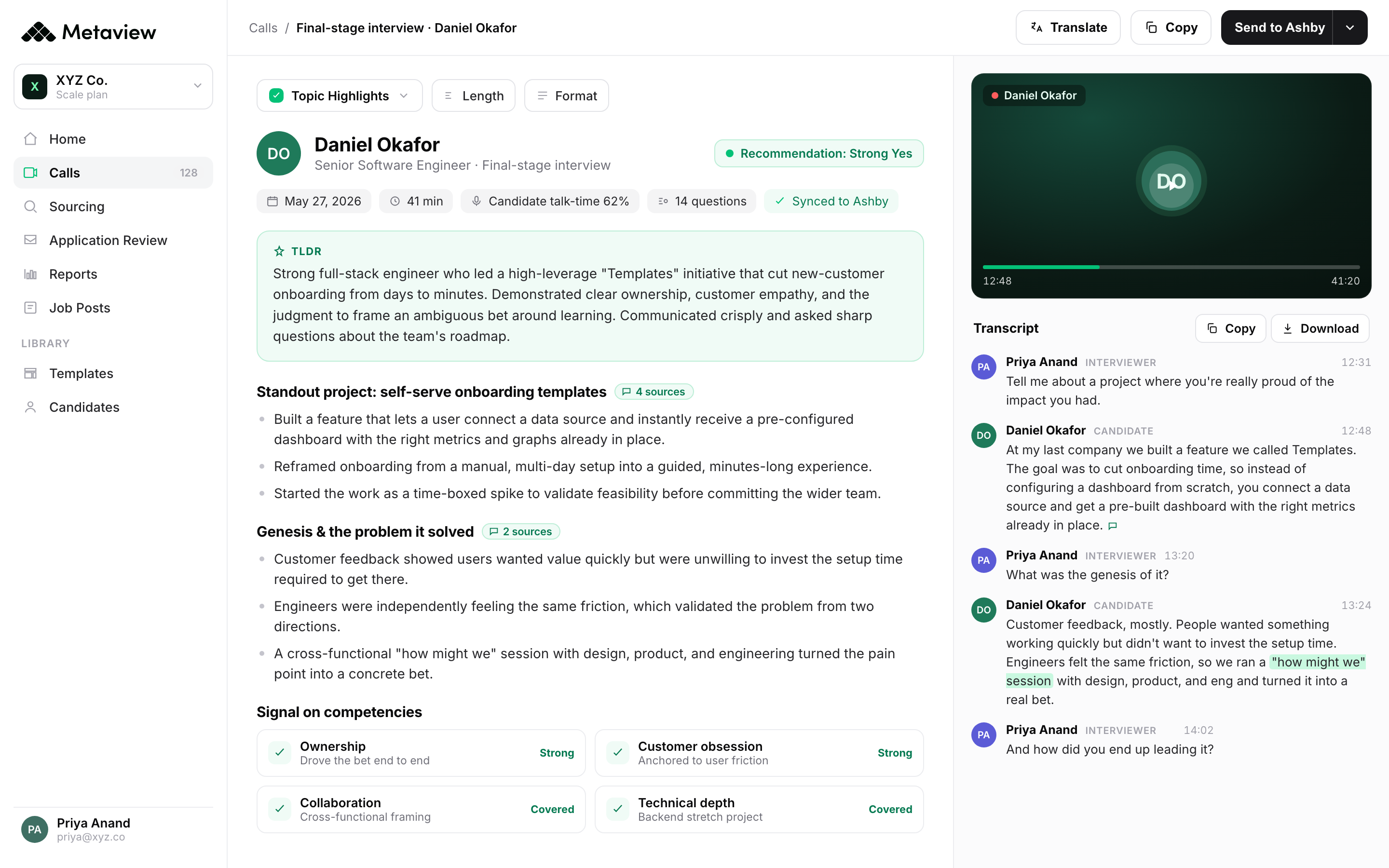
The screenshot above is where the calibration signal originates. Every recruiter screen, every engineering panel, every hiring manager debrief becomes a labeled data point that the AI Sourcing agent reads on the next search.
Manual sourcing vs Generic AI vs Calibrated sourcing
Most teams pick a side in a binary debate: 'use ChatGPT for sourcing' versus 'do not use AI for sourcing.' That is the wrong frame. The honest contrast is between three operating models: manual Boolean sourcing, generic AI assistance bolted on top of manual sourcing, and a calibrated AI sourcing agent that reads your owned data. Here is how the three compare on the dimensions that matter.
| Dimension | Manual sourcing | Generic AI | Calibrated AI sourcing |
|---|---|---|---|
| Query layer | Hand-written Boolean strings | Prompt-engineered LLM call | Natural-language description, run against ATS, past interviews, and external |
| Source of truth | Sourcer's mental model | LLM training data | Your team's accept/reject feedback on every past candidate |
| What improves over time | Sourcer's intuition | Nothing. Each prompt is fresh. | The ideal candidate profile, with every interview |
| Outreach grounding | Public profile only | LLM-generated, often hallucinated | Verified context from your past conversations and ATS |
| Failure mode | Reply rate plateaus | Plausible-but-wrong personalization | Slow to start, compounds quickly |
| Best for | Single high-stakes searches | One-off content tasks | Programs running multiple roles, indefinitely |
How AI changes technical sourcing, and what 'AI-native' actually means
AI-native is overused. Inside Metaview, we use the phrase to mean something specific: a sourcing program where AI is the primary surface, not a sidecar tool. The recruiter does not have a separate 'AI tab' in their workflow. The sourcing agent is the workflow. It runs in the background between searches, ingesting every new interview, every new accept/reject, every new rejection reason, and refreshing the ideal candidate profile in real time.
Concretely, that means: the sourcer's first action of the day is not writing a Boolean string. It is reviewing the agent's overnight progress on the searches it was already running, accepting or rejecting the candidates it surfaced, and adjusting the natural-language description if the agent went off-track. The Boolean string never gets written.
The video above shows where this gets concrete: the sourcing agent does not just search the open web. It searches across your owned data, your ATS records, your past Metaview interview conversations, your team's notes, and reconciles all of that against the natural-language target you set. The candidate it surfaces is one you have already touched, or one your hiring manager has effectively scored without realizing it.
How Metaview wires interview signal back into sourcing
Here is how the loop works in practice when Metaview is the system. Every screen, panel, and debrief is captured by Metaview's Notetaker. The recruiter and the hiring manager get structured notes, scorecards autofill from the conversation, and the rejection reason gets written back to the ATS automatically. That structured signal then becomes the working memory of the AI Sourcing agent.
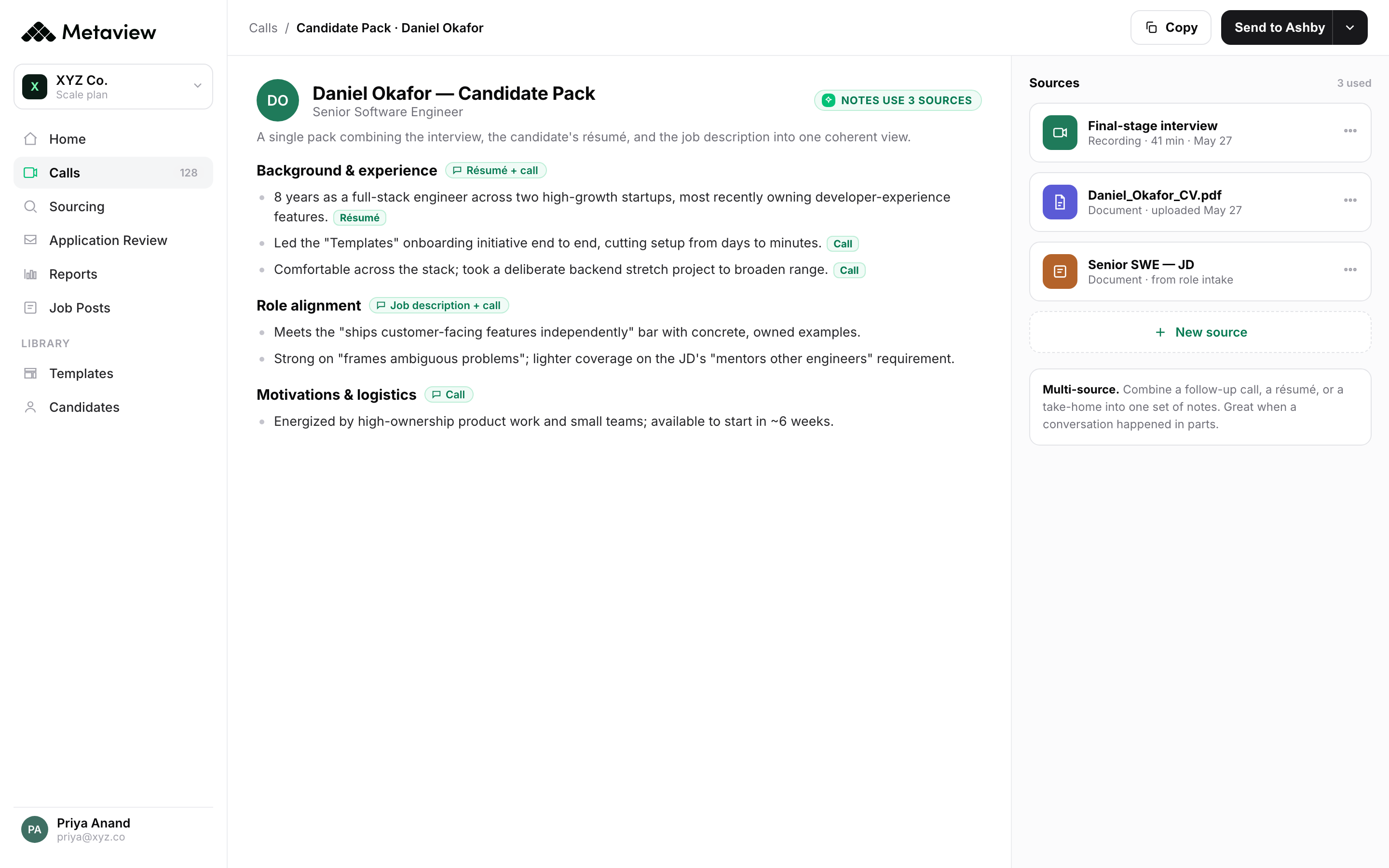
When the sourcer kicks off the next search, the agent already knows: who from the candidate's prior company has been interviewed by your team in the last 12 months, what came up, who passed, who did not, and why. Suggested Follow-ups let the sourcer drill in further. Candidate Reasoning, the short LLM-generated summary on every candidate card, explains exactly why the agent surfaced this person and which past signals influenced the choice. An 80% to 90% precision rate by the third calibration loop is not magic. It is compounding feedback.
Metaview Sourcing is very good, genuinely, the best bit of AI kit, and we've trialled loads.”
What 'great' looks like: a 6-step technical-sourcing operating model
If we had to compress what AI-native technical sourcing looks like into a 6-step operating model, it would be this. Treat it as a checklist for your next sourcing program design, or as a self-audit on your current one.
- Capture every engineering interview by default. Recruiter screens, hiring manager debriefs, panel rounds, takeoffs. Manual notetaking is the leak in the system, because the calibration signal disappears into a person's head.
- Make the ideal candidate profile a living document. Not a JD. Not a sheet. A working surface that updates with every accept/reject decision your team makes.
- Run sourcing against owned data first. Your ATS, your past Metaview conversations, your team's notes. The signal-density is orders of magnitude higher than the open web.
- Let the agent run in the background. A search does not need to be a sprint. Background subagents refresh candidate lists continuously, so the sourcer's role is reviewing and accepting, not crawling and Boolean-stringing.
- Tie the rejection reason to the next search. Every rejected candidate should sharpen the next list. If your ATS rejection reasons are vague freetext, the calibration signal is being thrown away.
- Run sourcing as a program, not a campaign. A program compounds. A campaign resets every time. The teams winning in 2026 ran their sourcing program for 18 months before they had results worth showing.
 Metaview
MetaviewThe full unlock: a sourcing agent that reads inside your owned data, not just the open web.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.