

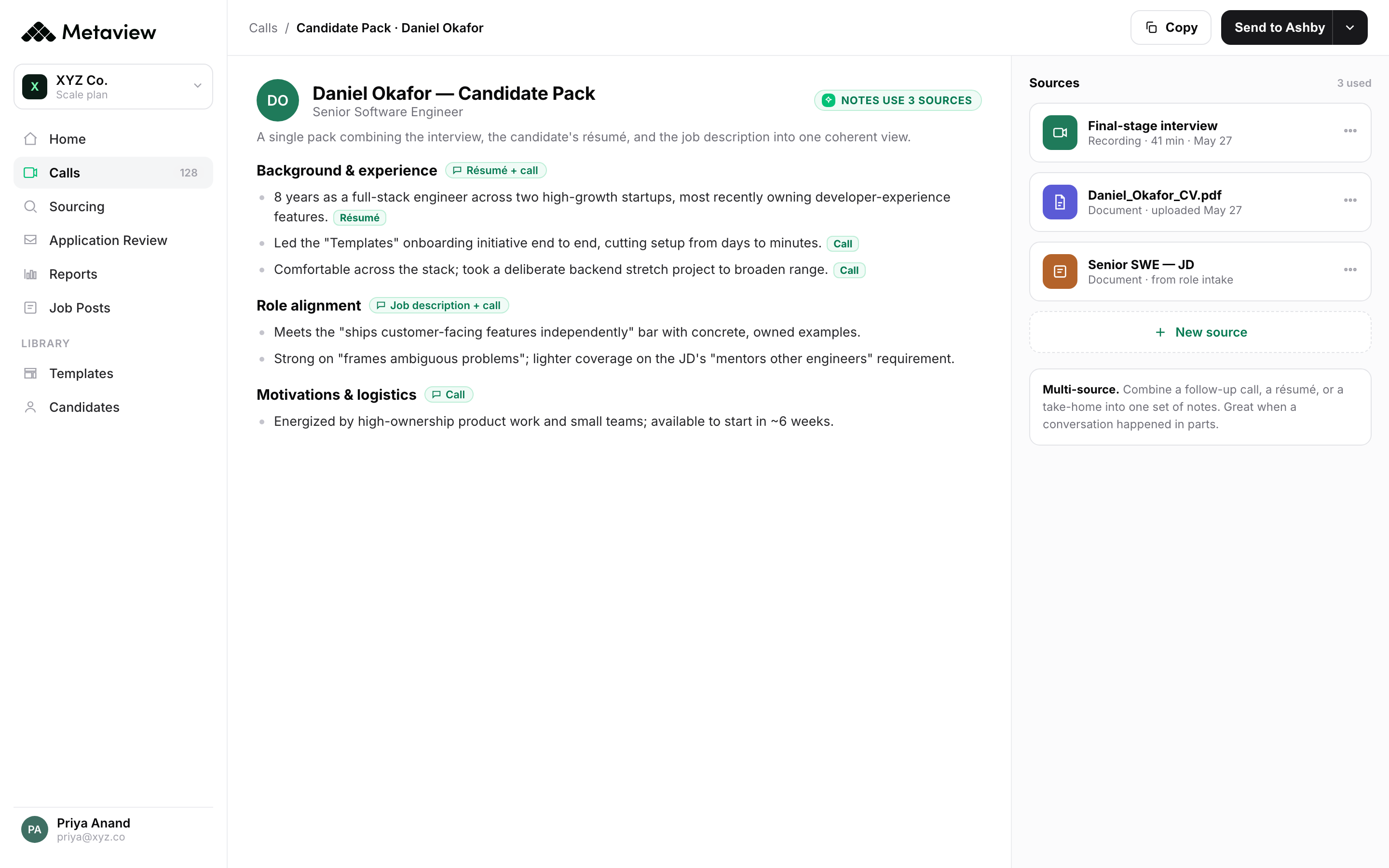
- 1Verbatim candidate response captured live, time-stamped to the panel.
- 2Each phrase auto-tagged to the competency it answers, not the keyword it contains.
- 3Panel-wide rating aggregates the evidence so debriefs compare quotes, not impressions.
Most hiring teams treat candidate scoring like a paperwork problem. Add a scorecard, define a 1-to-5 scale, ask interviewers to tick boxes, and assume consistency follows. It does not. Scoring is an evidence problem, not a scorecard problem, and the gap shows up the moment two interviewers rate the same candidate differently and nobody can rewind the conversation to settle it.
Why scorecards alone don't fix scoring
Scorecards have been the recommended fix for inconsistent hiring decisions since the 1990s. Define competencies, attach a rating scale, ask every interviewer to score the same way, and scoring variance is supposed to shrink. In practice it does not, because the scorecard captures the rating without capturing the reason for the rating.
When the debrief opens, the panel sees a row of 3s and 4s with no shared way to test them. One interviewer's 4 was anchored to a specific behavior the candidate described in minute 22. Another interviewer's 4 was anchored to an overall feel about communication style. Both look identical on the scorecard. Both lead to a hire decision. Only one of them is defensible six months later when the hire underperforms and somebody asks how the team got there.
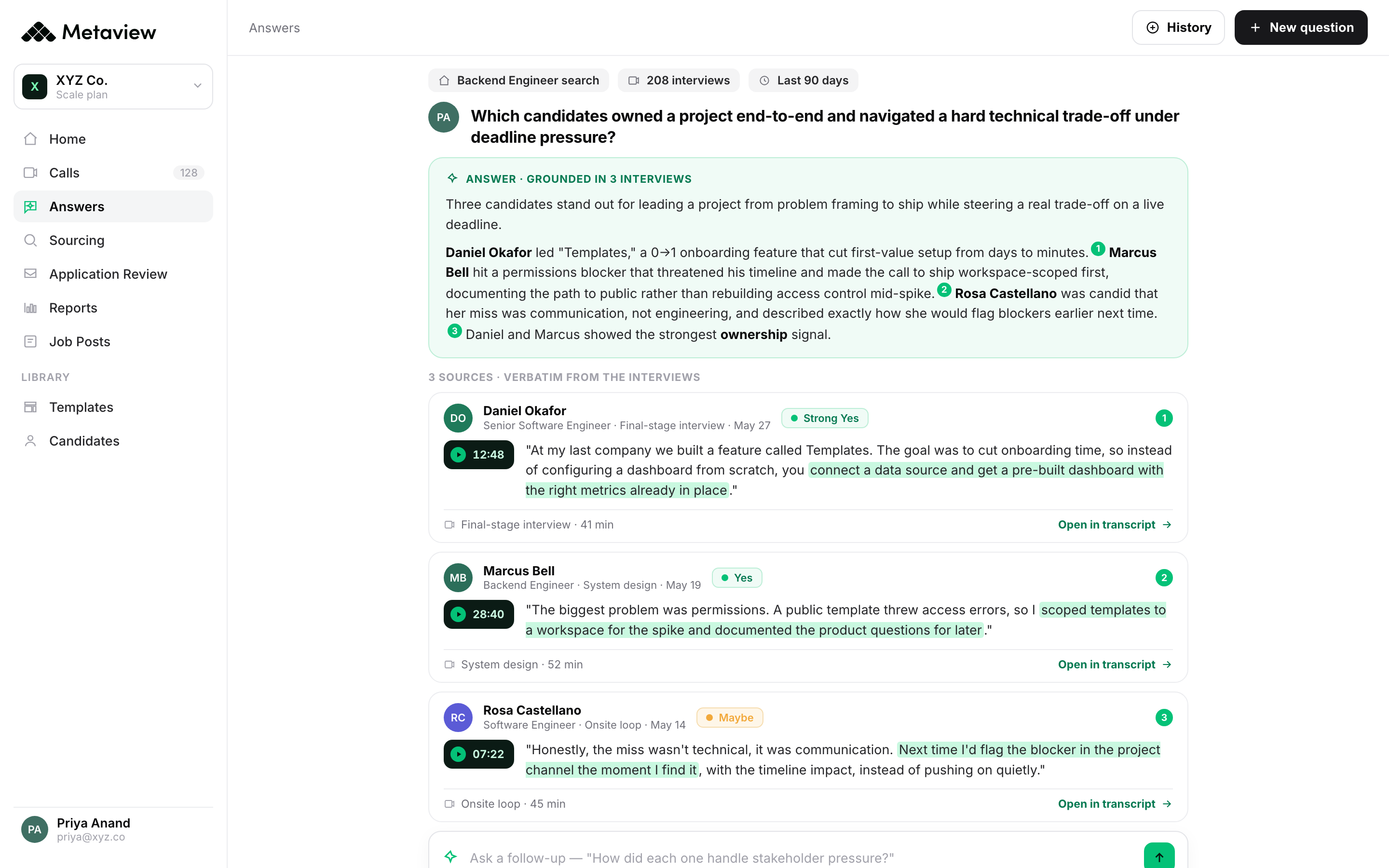
The according to Metaview's 2026 AI & Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA makes the cost visible. Teams that don't use AI in hiring report that only 49% of searches start with high alignment. Teams where AI is core jump to 68%. The gap is not a tool gap. It is an evidence gap. AI-core teams capture the intake conversation, the interview conversations, and the debrief together, so the panel sees the rating and the reason as one record. Everyone else is reading a scorecard and reconstructing the reasoning from memory.
- Each interviewer brings a slightly different bar to the same role.
- Debrief turns into a memory contest, not an evidence comparison.
- A strong-yes from your best interviewer reads identical to a strong-yes from your weakest.
- Disagreements get resolved by seniority in the room, not by signal.
- New interviewers ramp slowly because the bar lives in people's heads.
- Every interviewer scores against the same defined competencies on the same scale.
- Each rating links to a verbatim quote from the conversation that produced it.
- Panel-wide variance is visible in the dashboard before the debrief, not after the offer.
- New interviewers see the bar from their first call because the calibration is shipped with the template.
- Debriefs compare evidence, not impressions, and finish in 15 minutes.
For every candidate Gasper gave a strong yes, 87% ended up with the offer. Doesn't matter if it was a values or coding interview, strong yes meant offer. So I dumped all his transcripts into ChatGPT to extract the actual behaviours that distinguished strong-yes from yes from fail. Three hours of work on a Friday night.”
The 4 components of a defensible score
A defensible candidate score is not a number. It is a number plus the conversation that produced it plus the rubric that interpreted it plus the calibration that aligned the panel on what each level of that rubric means. Strip any of those four out and the score stops being defensible the second somebody questions it.
Rubric: the bar that exists before the role opens
The rubric is the set of competencies the role will be measured against and the levels each competency can be rated on. It has to exist before the first candidate is sourced, not after the first interview ends. Defining the rubric mid-search is how panels end up scoring different competencies for the same role and treating that as agreement. A 4-level scale outperforms a 5-level scale because it forces a directional choice. There is no comfortable middle to retreat to.
Evidence: the quote that backs the rating
Every rating has to link to a specific candidate response. Not a paraphrase, not an interviewer's interpretation, the candidate's verbatim words at a specific timestamp in the conversation. Without this link the rating is a feeling. With it, the rating is testable. When a hiring manager challenges a 4, the recruiter can pull the 90 seconds of conversation that produced it. When a 4 turns into an underperforming hire, the team can rewatch the evidence and figure out what they over-weighted.
Calibration: the same level means the same thing across the panel
Calibration is the discipline of forcing the panel to agree on what a 3 looks like before they score a single candidate. Most teams skip it because it feels expensive. The cost is paid later, in offers extended to candidates the bar would have rejected if everybody had been scoring on the same scale. Calibration sessions take about an hour for a panel of 4. They pay for themselves the first time the team avoids a regrettable offer.
Audit trail: every decision linked to the conversation that produced it
The audit trail is what turns a hiring decision from an opinion into a record. Six months after the hire, when performance is good or bad, the team needs to be able to walk back to the original interviews and ask which signals predicted the outcome and which did not. Without that loop, the rubric never improves. With it, the rubric gets sharper every quarter and the hiring system compounds.
Where scoring usually breaks
Scoring breaks at three predictable points. Knowing where each break happens makes the fix specific, not theoretical.
Break 1: Intake doesn't define the bar
If the kickoff conversation between recruiter and hiring manager produces a job description and a list of skills but no defined rubric, every downstream interview will produce a slightly different scoring model. The fix is to treat intake as the calibration session. Define the rubric, agree on what each level looks like, and capture the conversation so every interviewer joining the panel later can hear it.
Break 2: Notes during the interview destroy signal
Interviewers who type during the call miss the candidate's eyes, body language, and the specific phrasing that signals depth. Interviewers who don't type lose the verbatim quote that would later anchor the rating. Both versions break scoring. The fix is a notetaker that captures the conversation verbatim and lets the interviewer stay present so they can probe the answer instead of transcribing it.
Break 3: Debrief turns into a memory contest
Without linked evidence, the debrief defaults to whoever in the room has the strongest recall or the most seniority. The fix is to walk the panel through each competency, surface the evidence each interviewer scored against, and resolve disagreements by comparing quotes, not by deferring to the hiring manager's gut.
Define the bar before the role opens. Templates ship with competency definitions and a 4-level scale, so the bar arrives with the role, not after the panel disagrees.
Auto-pin verbatim candidate responses to the competency they answer. Every rating links to the 90 seconds of conversation that justified it.
Capture the calibration session itself. New interviewers see how the panel scored the first 5 candidates against the rubric, then ramp from there.
Six months after the hire, walk back to the original evidence and see which signals predicted performance. The rubric sharpens every quarter.
What a 1-hour calibration session actually looks like
Most teams describe calibration as something they should do and then never schedule. The reason is usually that nobody on the panel knows what the agenda looks like. So here is the agenda.
Minute 0 to 10: read the rubric out loud. The recruiter walks the panel through the 4 competencies and the 4 levels of each. Out loud, on a shared screen, in the same room. The point is to force every interviewer to actually look at the wording rather than assume they remember it from the intake email.
Minute 10 to 30: score the first candidate independently. The panel each watches or listens back to the same 15-minute interview segment from a prior search. Everybody scores the candidate on each competency without discussion. The scores get shared on a single screen at the end of the segment.
Minute 30 to 50: argue from evidence, not from impressions. Wherever the scores diverge by more than one level, the panel rewinds to the candidate response that produced the higher score and discusses why the lower scorer rated it differently. Nobody is wrong. The point is to make the disagreement visible so the rubric can absorb it.
Minute 50 to 60: rewrite the level definitions. If the panel learned that level 3 of 'systems thinking' meant something different to each interviewer, the level definition gets rewritten before the next candidate enters the funnel. The rubric is not a one-time document. It is a living artifact that absorbs every calibration session.
How Metaview turns conversation into scoring evidence
Metaview sits in the interview as a structured notetaker. It transcribes verbatim, tags each candidate response to the competency it answers based on the rubric the team defined at intake, and writes a structured summary that maps directly to the scorecard the panel uses to rate the candidate.
The practical change for the recruiter: after every interview, the scorecard arrives pre-filled with the candidate's verbatim responses pinned to each competency. The interviewer reviews the evidence, assigns a rating, and the rating is permanently linked to the underlying quote. When the hiring manager opens the debrief, they see the rating and the quote side by side. When the panel disagrees, they replay the 90 seconds and resolve the disagreement on signal, not memory.
The practical change for the hiring manager: the rubric they helped define at intake is the rubric the recruiter scored against. The competency names match. The level definitions match. The evidence is auditable. The debrief stops being a re-negotiation of what the role required and becomes a comparison of how well the candidate matched it.
The practical change for the TA leader: panel-wide variance, interviewer drift, and competency-by-competency scoring distributions all live in the same dashboard. The first interviewer who consistently rates 4s across the board becomes visible in week 2, not quarter 4. The first competency that nobody knows how to score becomes obvious before it produces a bad hire.
We've saved about 45 minutes per interview by implementing Metaview as an AI notetaker. Easy breezy! And yes it would take about an hour to produce the candidate report before.”
Your 14-day rollout
The fastest way to operationalize structured scoring is to pick one role, ship the rubric, run the calibration session, and let the first 5 candidates teach the panel where the bar lives. Here is the 14-day version.
- Day 1. Pick a single role that will run 5 or more interviews in the next two weeks. Engineering or sales work best because volume builds the calibration sample fastest.
- Day 2. Hiring manager and recruiter define 4 competencies for the role on a 4-level scale. Each level gets a one-sentence behavioral anchor.
- Day 3. Ship the rubric into the interview template so the structure travels with every panel.
- Day 4. Run the 60-minute calibration session against a prior candidate's recording or transcript. Rewrite level definitions where the panel disagreed.
- Day 5 to 12. Run the next 5 candidates through the rubric. Every interview is recorded, every response is auto-tagged to the rubric, every rating links to a verbatim quote.
- Day 13. Pull the variance dashboard. Identify any interviewer who scores 4 on more than 80% of candidates or 2 on more than 80%. Coaching conversation happens before the next requisition opens.
- Day 14. Debrief the rubric itself with the hiring manager. Which competencies predicted the strongest candidates? Which were noise? Sharpen for the next 5 candidates.
At the end of 14 days the team has 5 scored candidates with linked evidence, a calibrated panel, a sharpened rubric, and a dashboard that surfaces drift before it produces a bad hire. That is the candidate scoring system most teams have been trying to build for years through process documentation and templates alone.
A 2-minute walkthrough of how Metaview turns the conversation into a scored, auditable record.
Frequently asked questions
What is candidate scoring?
Candidate scoring is the practice of rating candidates against a defined rubric of competencies, with each rating anchored to specific evidence from the interview. The scorecard is the form; scoring is the practice underneath it.
How is candidate scoring different from a scorecard?
The scorecard is the document that captures ratings. Candidate scoring is the system that produces defensible ratings, with four components: rubric, evidence, calibration, and audit trail. A scorecard without an evidence layer is a paperwork exercise.
How many points should a candidate scoring scale have?
Four works better than five. A 4-level scale forces a directional choice, while a 5-level scale invites interviewers to retreat to the comfortable middle. Each level should have a one-sentence behavioral anchor, not just a numeric label.
What's the most common candidate scoring mistake?
Rating without anchoring the rating to specific candidate evidence. The rating becomes a feeling, the debrief becomes a memory contest, and the team has no way to audit the decision six months later when performance data lands.
How long does it take to roll out structured scoring?
Two weeks for the first role with Metaview templates. Day 1 is rubric definition, Day 4 is the calibration session, Days 5 to 12 are 5 candidates through the rubric with linked evidence, Days 13 and 14 close the loop on interviewer drift and rubric sharpening.