

A new Head of Talent inherits a 60-req quarter on a Monday. Three days in, she runs the inventory. The ATS holds 12,000 past applicants she has never been able to search. Three open-web sourcing campaigns run in parallel.
The recruiter on her team rebuilds the same boolean string from scratch every fourth week. Six months later, time-to-fill on senior roles has crept past 45 days, and the hiring managers are escalating.
The team is not bad at sourcing. The system underneath them is not built. The pipeline is not holding because there is no substrate for it to hold to.
A high-performing acquisition pipeline is not a sourcing campaign you run harder. It is a system you build under the recruiter.
A data layer that turns every interview into searchable signal. A channel mix chosen by where your hires come from. An always-on AI sourcing layer that starts with the candidates you already own. And a talent pool you have already vetted.
The substrate compounds; the campaign resets.
Why high-performing pipelines beat sourcing campaigns
Most teams treat sourcing as something the recruiter does. Channels open, outreach goes out, candidates trickle in, the cycle resets at the next req. The output is real, but the value lives in the recruiter's head and in the messages she remembered to send.
When she leaves, or the role shifts, or the volume doubles, the cycle starts from scratch.
High-performing teams treat sourcing as something the system does, and the recruiter directs. The work she puts in compounds because the data layer underneath her holds every signal she generates, ready for the next search.
Campaigns reset; systems compound. That is the investment-versus-cost line the buying decision sits on, and it shows up in the numbers.
According to Metaview's 2026 AI Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, teams that put AI at the core of hiring are not running faster sourcing. They are running a different kind of system.
The numbers all point the same way. The teams running sourcing as a system are aligned earlier, hold relationships better, and feel the lift before their hiring managers ask for it.
The teams running it as a campaign are still scrambling at the same kickoff their counterparts already aced.
The four layers under a high-performing pipeline
Most teams that audit their pipeline converge on a similar shape. The ones that win combine four layers; the ones that do not end up running channels without signal underneath them. The system is the layers together, not any one of them in isolation.
- Owned interview signal. Every screen, panel, and intake call becomes structured data, anchored to skill, fit, and what the candidate said in their own words. The corpus that compounds the more interviews your team runs, and the substrate every downstream layer stands on.
- The channel mix. Three to six channels chosen by where your hires come from, not where outreach is easiest. Referrals, ATS rediscovery, AI sourcing, careers page, niche communities, internal mobility, picked by signal density and held across cycles, not cycled in and out by trend.
- An always-on AI Sourcing layer. An agent that runs across whichever channels you keep, sources from your owned corpus first, and refreshes candidate pools daily while the recruiter focuses on engagement and judgment. One searchable corpus, not five tabs open at once.
- The talent pool you have already vetted. Past applicants you have already screened, silver medalists from prior loops, dormant candidates the recruiter built rapport with eight months ago. The highest-signal warm pool you own, and the one most teams forget exists until the next urgent req opens.
The four interlock. Skip one and the others lose leverage. Without owned signal, the AI sources blind. Without the channel mix, the signal points nowhere. Without the AI layer, the pool ages out faster than the recruiter can search it. Without the pool, every search starts cold.
Five disciplines that keep the system honest
The layers are the architecture. The disciplines are how a TA leader keeps the substrate live across reqs, recruiters, and quarters. Five moves, in the order that matters.
1. Define the ICP from interview data, not the JD
A job description is what the hiring manager thought she needed when the role opened. The ICP is what the people you have hired into similar roles look like, anchored to the conversations that landed them.
The first move every cycle is the calibration that pulls from your owned interview corpus, not the spec the JD inherited from the last open req.
Three concrete behaviors. Read the structured notes from the last three hires into the same role. Pull the skill clusters and competency signals those candidates landed on.
Bring them to the kickoff with the hiring manager as a draft persona, and let her sharpen it against her own gut. The ICP is calibrated, not invented, and the search starts honest.
2. Prioritize channels by signal density, not outreach volume
The audit every TA leader runs against her own historical data tends to converge. Six channels stay in the rotation more often than not: employee referrals, ATS rediscovery, AI sourcing, the careers page, niche communities, and internal mobility.
The mix shifts by role family and stage, but the shape holds. Signal density beats volume: a channel that delivers one hire every three months at high quality beats one that delivers a hundred applicants who do not match the ICP.
Cut channels by what your data shows. Most teams that run the cut find one or two channels they were investing in by habit, not by hire outcome. The recovered hours go back into the channels that compound, and the talent map gets sharper every cycle.
3. Capture every conversation as structured data
The interview corpus is only as good as what you put into it. Every recruiter screen, every panel, every intake call, every customer reference becomes structured signal the moment it happens, or it becomes a memory the recruiter reconstructs later from notes.
The data layer is built one conversation at a time. The discipline is making the capture the default, not an extra step.
Our Notetaker runs in the background of every interview, structures notes against the role's scorecard, and writes them back to the candidate's profile before the recruiter opens the next call.
The conversation becomes searchable signal automatically. The recruiter's job stays on the candidate in front of her.
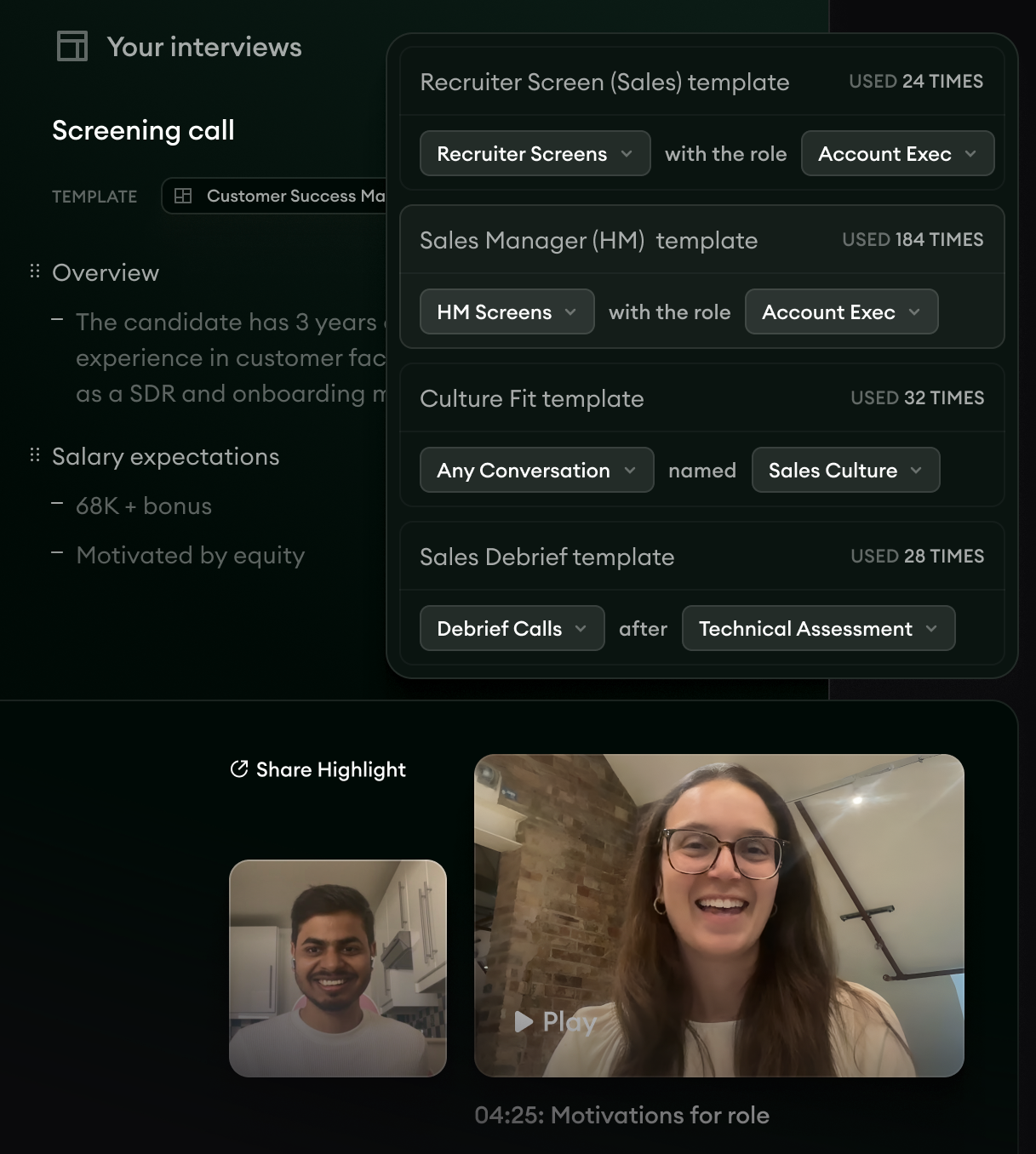
- 1Structured notes anchored to the role's scorecard, written automatically as the conversation happens.
- 2Topic chips surface the themes the candidate landed on, ready to query later.
- 3The full conversation stays linked, so the signal traces back to the source the moment a hiring manager asks.
4. Run AI sourcing against your owned corpus first
The default sourcing motion sends the AI agent to the open web first. The substrate sourcing motion sends it to your owned corpus first, then the web.
The two motions converge on the same final shortlist, but the discipline of starting with what you already own changes the math.
Most teams discover that the candidate the AI agent would have spent three days finding on LinkedIn already sat in their ATS, eight months ago, screened and passed on for a different role.
The agent runs the search against the structured interview signal, the past-applicant pool, and the open web in that order.
The recruiter gets a ranked shortlist with the corpus-first candidates surfaced at the top. The hours she would have spent on cold web sourcing go back to engagement and judgment.
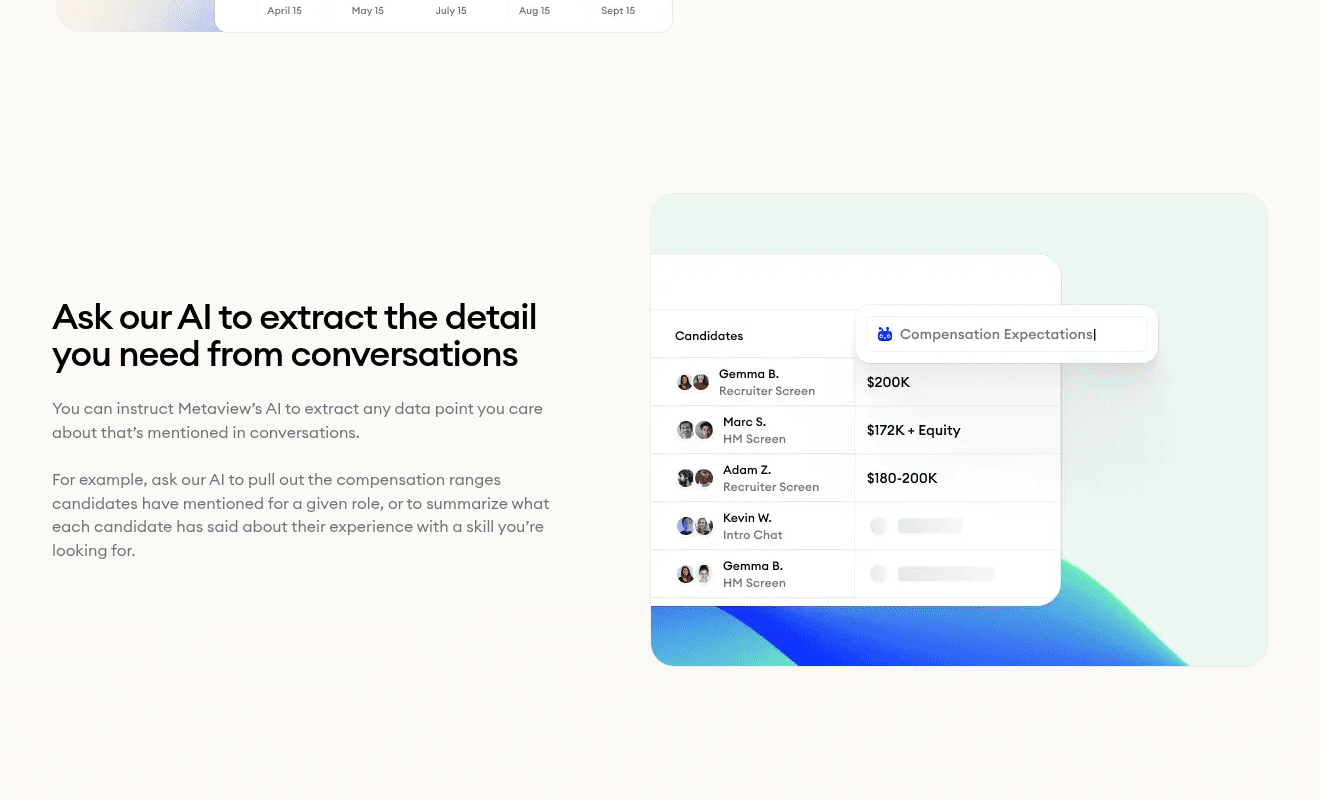
- 1Natural-language query against your owned interview corpus, in the recruiter's own words.
- 2Results surface candidates the recruiter has already met, ranked by signal match to the role.
- 3The web sweep runs underneath, but the owned-corpus shortlist lands first.
5. Measure the pipeline as a system, not per req
Per-req metrics tell you whether the next role closes on time. System metrics tell you whether the pipeline is getting healthier with every cycle.
The TA leader who measures both knows where to invest. The one who measures only per-req keeps optimizing the current sprint and watches the substrate slowly erode.
Leading indicators that matter: signal density per req (how many candidates surface with a clear ICP match on the first query), share of hires from the owned pool versus cold outreach, time from intake to first shortlist, recruiter NPS on the data layer's trustworthiness.
Lagging indicators stay the same, but you finally know which dials moved them. Reports in our AI Sourcing suite surface the patterns across reqs, interviewers, and quarters, so the system claim is something you can prove instead of pitch.
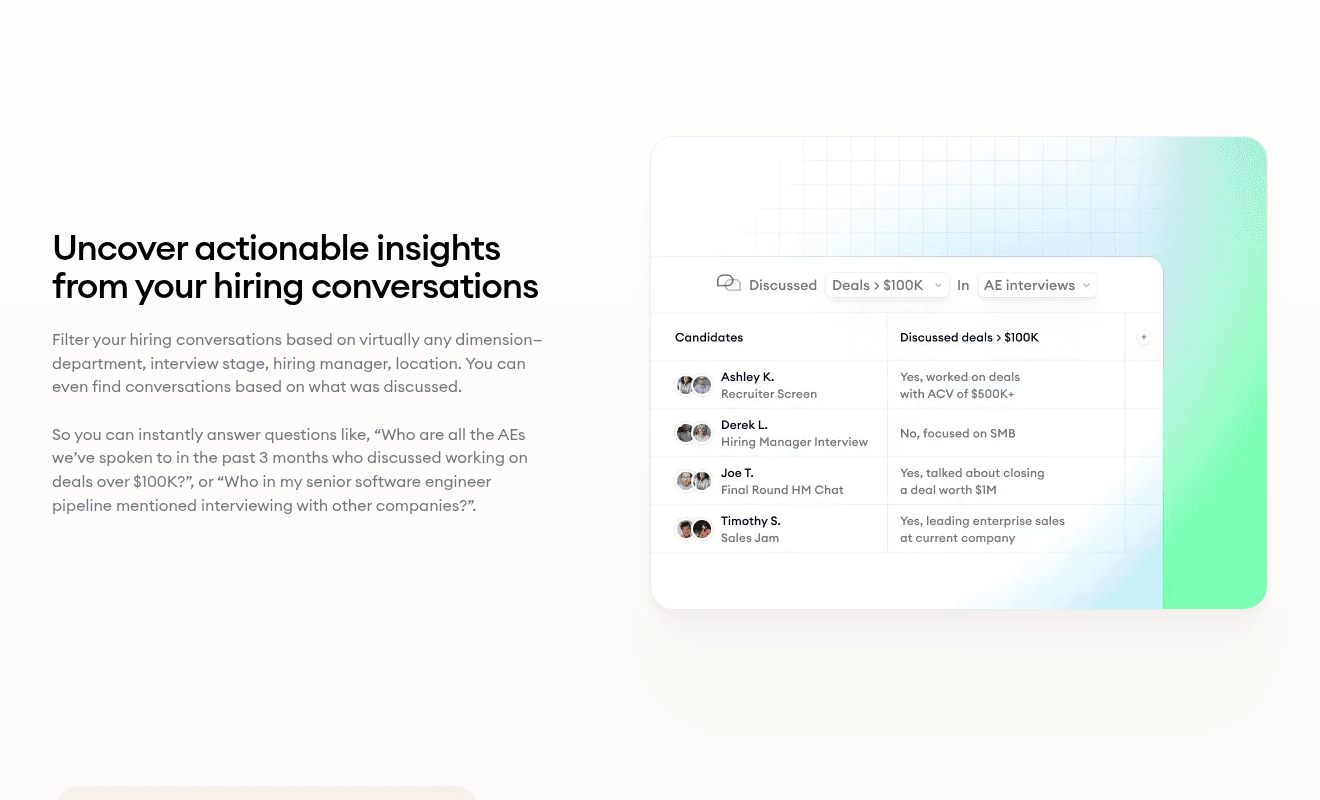
- 1Cross-cycle patterns by role family, surfaced from the interview corpus rather than per-req exports.
- 2Signal-density trends per channel, so the channel mix tunes itself against real outcomes.
- 3Per-interviewer signal capture, so the substrate stays consistent regardless of who runs the call.
Where Metaview compounds across the layers
The disciplines compound when the substrate compounds. The customers that ran the playbook longest see it most clearly.
The team stops rebuilding the same searches. The recruiter stops scrambling on cold reqs. The hiring managers stop asking why the same role takes a different shape every quarter.
We have completed over 1,900 calls using this platform, saving 77 full workdays. We are not just automating note-taking. We use the multi-source feature so each interviewer goes in unbiased but informed enough to cover new ground.”
The contrast lands sharper when you put the two motions side by side. The campaign pipeline runs hard and resets; the system pipeline holds. The data layer carries, and the recruiter spends her hours on the work only she can do.
- Channel choices reset every quarter
- Signal lives in a recruiter's head, not the corpus
- Past applicants invisible after the first scan
- AI sources only from the open web
- Time-to-fill creeps without a pattern to fix
- Channels chosen by signal density and held across cycles
- Every interview structured into searchable signal automatically
- Silver medalists surface on the first query of every new req
- AI sources from your owned corpus first, then the open web
- Time-to-fill compounds down as the data layer grows
The pipeline that holds is the one with the substrate underneath it. Campaigns can deliver a quarter; only systems deliver a year. For a TA leader designing the function, the lever is not more sourcing, it is better foundations.
Bring the four layers together, run the five disciplines as the operating cadence, and the pipeline starts behaving like the asset it should have been from the start.
The pipeline that holds is the one the next recruiter inherits ready, not the one she has to rebuild from scratch.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Frequently asked
What is the difference between a talent sourcing strategy and a high-performing pipeline?
The talent sourcing strategy is the playbook the recruiter executes inside the function. The high-performing pipeline is the architecture the TA leader designs around her: the data layer, the channel mix, the always-on AI layer, and the talent pool that make the playbook compound instead of reset.
How long does it take to build the data layer from a generic ATS setup?
Initial integration with Greenhouse, Ashby, Lever, or Workday usually runs four to six weeks, depending on your team's ATS hygiene and how many interview surfaces you bring online at once. The substrate starts paying off as soon as the first cycle of interviews lands in the corpus; the compound effect on signal density and time-to-fill shows up around the 90-day mark.
Does AI Sourcing replace recruiter judgment, or augment it?
It augments. The AI handles the mechanical work that drains recruiter hours: pulling candidates from the owned corpus, ranking against the ICP, refreshing the pool daily. Final shortlist calls, calibration with the hiring manager, and outreach personalization stay with the recruiter, where judgment beats automation every time.
How do we know the pipeline is high-performing?
Leading indicators tell the truth before the lagging ones catch up: signal density per req on the first query, share of hires from the owned pool versus cold outreach, time from intake to first shortlist, recruiter NPS on the data layer's trustworthiness. Reports surface the patterns across reqs, interviewers, and quarters, so the system claim is measurable instead of intuited.
Can a small team (1-2 recruiters) build this, or is it only for enterprise?
Small teams get the most leverage from the data layer because there are fewer recruiters to scramble when the pipeline runs thin. Start with Notetaker and AI Sourcing connected to your ATS; the corpus builds with every interview, and the channel-mix audit happens naturally as the data lands. Reports and AI Filters earn their place as you scale past five open reqs at a time.