

Most teams treat interviewer bias as a training problem. Send the team to a workshop, raise awareness, and the rest sorts itself out. Awareness without evidence is private impressions in better packaging. It doesn't survive contact with a debrief.
The teams that actually close bias treat it as a system problem. They run interviews on shared evidence, not on memory. Structured questions, anchored rubrics, captured behavior, calibrated panels. Each layer compounds the next.
Here's how that system runs, why each layer earns its place, and where Metaview's AI Notes, Reports, and Application Review fit as the data layer that makes it auditable.
Why awareness alone doesn't close bias
Walk into any hiring kickoff and you'll hear the line: we just need to be more aware. Awareness is the polite framing. It's not the fix.
A hiring manager who's aware of affinity bias still walks out of a 45-minute conversation having formed an opinion on six things. Most of that opinion sits in their head as a feeling, not as evidence anyone else can read.
The gap shows up when the team compares notes. One interviewer remembers the candidate as sharp on systems thinking. Another remembers them struggling to commit to a position. Both could be right.
Without the actual behavior captured in shared form, the debrief becomes a negotiation between memories.
The cost lands in three places. Qualified candidates get filtered out for reasons unrelated to the role. The hires that land cluster around whoever resembles the existing team. Every biased interview makes the next one less consistent.
The data on what this looks like at the team level is uncomfortable.
According to Metaview's 2026 AI Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, the surface story and the underlying reality of cross-functional hiring relationships don't match.
Surface alignment is what you get when two people who don't fully trust each other's judgment are both polite. Real alignment is what you get when the same evidence is in front of both of them.
The system that closes bias is the same system that closes that trust gap. Same problem at different scales: judgment running on private impressions instead of shared signal.
Where bias actually shows up in interviews
Before the system can do anything useful, you have to know the patterns it has to catch. Bias rarely announces itself. It shows up as five recurring shapes, each easy to mistake for normal interviewer instinct, each fixable by something a layer above it.
Naming these patterns isn't the fix. Recognizing them in real interviews is the prerequisite. Recognition happens on a specific candidate, against a specific question. That's the work the next four layers do.
The four layers of a bias-resistant interview system
The four layers below aren't a menu. Each one feeds the next. Pick one and you'll get a marginal lift. Run them as a system and the bias your interviewers used to wrestle with privately becomes evidence the whole team can review.
1. Structured questions, asked the same way
Drift starts at the question. When every interviewer ad-libs their own version of "tell me about a hard project," the team ends up comparing five different answers to five different prompts. The best candidate becomes whoever drew the friendliest interviewer.
A structured interview locks the question set, the order, and the rubric anchor. Same prompt, same probe sequence, same answer criteria. The structure is in the rubric, not in the interviewer's tone. Conversational delivery and structured evaluation are independent layers.
This is also where the right interview questions earn their place. A bad question (are you a good multitasker?) invites a fluent candidate to perform. A good question (walk me through how you prioritized when three deadlines hit the same week) forces specific evidence.
2. Evidence-anchored scorecards
A scorecard that says "problem-solving: 1-5" is a permission slip for gut feeling. A scorecard that says "identifies root causes, considers multiple solutions, explains reasoning clearly," with concrete examples of each rating level, forces the interviewer to cite the evidence.
That shift is also what makes calibration work, because two interviewers comparing notes now have something to point at. Interview rubrics aren't a documentation exercise; they're the thing that makes a debrief productive instead of a memory contest.
Building one is easier than it looks. Start with three must-haves and three must-nots for the role, then expand from the first five real candidates rather than authoring the perfect rubric on day one. Assessing the responses against those anchors gets sharper as the team runs it.
3. Calibrated panels that surface drift
Diverse panels balance perspective. Calibration sessions surface where the panel itself is drifting. Both matter; neither one alone closes the gap.
A diverse panel covers different functional angles on the role, different seniority levels, and different lived experiences of the work. Panel interviews work because one person's blind spot becomes another's obvious red flag.
Calibration is the recurring check that the panel is still rating the same behavior the same way. Pull two recordings where the panel disagreed sharply and walk through the evidence together.
The arguments that come out are where shared standards actually form. Without calibration, the panel becomes five interviewers running five private rubrics in parallel.
4. Captured behavior, surfaced patterns
The first three layers fix what happens inside one interview. The fourth makes patterns visible across many interviews, which is the only place systemic bias actually shows up.
When every interview is captured as structured behavior, the team can finally ask questions one debrief can't answer.
Does this interviewer rate communication style 1.5 times harsher for accented candidates? Are candidates from a particular school cluster getting an unfair lift across the funnel?
These patterns don't surface from training. They surface from data. The data layer is the only one that can audit the other three, which is why a system without it tends to regress quietly back to private impressions after a quarter or two.
Each layer compounds the next. Structured questions feed the rubric. The rubric feeds calibration. Calibration tightens what gets captured. Captured behavior surfaces patterns that send the team back to refine the rubric.
We elevated from gut-feel recommendations to evidence-based insights. Every scorecard and report looks and sounds consistent, regardless of who prepared it.”
How Metaview runs the system end-to-end
The four layers can run on paper. They run further when the evidence layer is automatic, the patterns surface themselves, and the shared question library lives where every interviewer already is.
- Each interviewer types their own notes during the call.
- Scorecards arrive hours later, reconstructed from memory.
- Debriefs negotiate between competing impressions.
- Drift across interviewers stays invisible.
- Every interview is captured as structured behavior.
- Scorecards write themselves from the conversation.
- Debriefs work from the same evidence base.
- Cross-interviewer patterns surface in Reports.
The capture layer comes from our AI Notetaker. Every interview lands as structured notes against the rubric the team agreed on, not as a transcript that needs interpretation. The interviewer can listen instead of type.
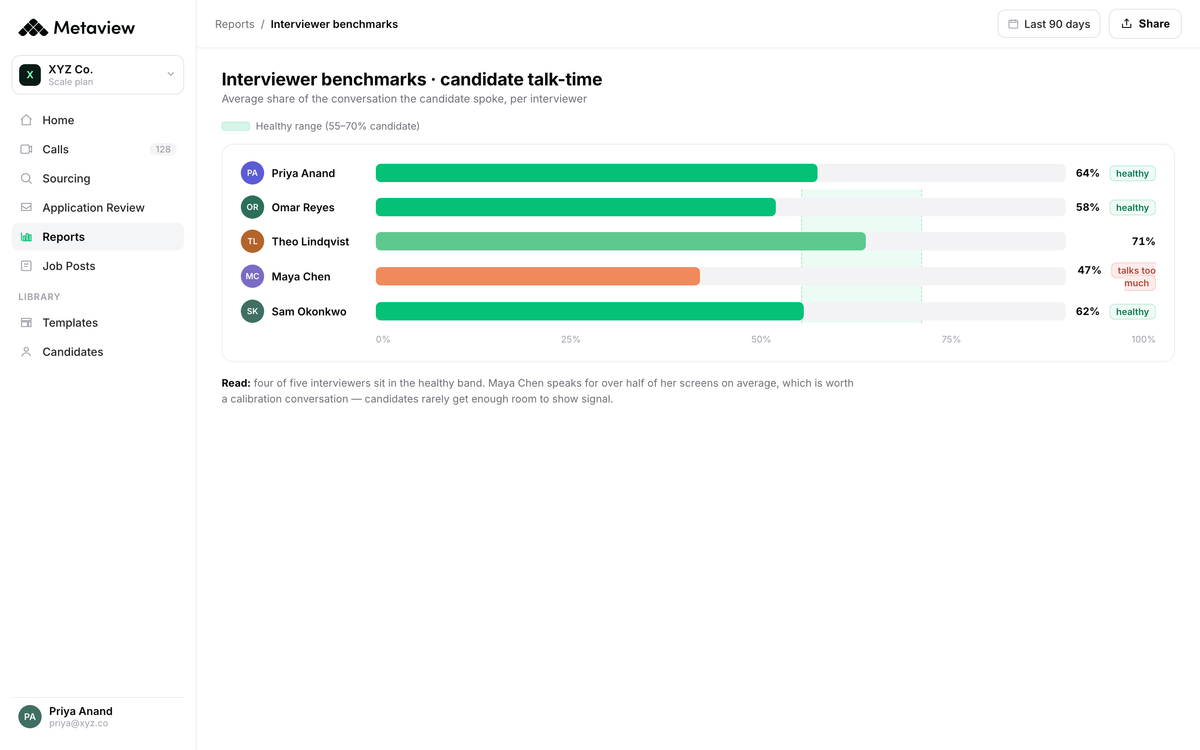
The pattern layer comes from Reports. The same evidence rolls up into cross-interviewer signal: who's running harder than the bar, who's running softer, where the rubric is doing its job. That's the audit layer the first three layers can't generate on their own.
The shared-question layer lives in Snippets, the library of interview questions and rubric anchors every interviewer can pull from. New interviewers run the same set as senior ones.
Application Review carries the same evidence backwards into top-of-funnel triage. The panel ends up calibrating against a smaller, cleaner pool.
Companies like Cockroach Labs, Quora, and Deel run Metaview exactly this way. The system isn't theoretical; it's how those teams decide who gets hired.
Frequently asked
Does AI introduce its own bias?
Not in the way the question usually implies. Our AI Notes captures behavior verbatim and runs pattern detection against your own rubric, not a generic "good interviewer" model. The bias the system surfaces is the bias your interviewers already have, made visible. The fix is in your hands; the AI just stops it from staying hidden.
Can structured interviews still feel human?
Structure lives in the rubric and the question set, not in the interviewer's tone. The conversational delivery and the structured evaluation are independent layers. Candidates feel a difference when the questions are sharper and the follow-ups calibrated. They don't feel a difference between a scored interview and an unscored one.
How do we get hiring managers to buy in?
Lead with the cost frame, not the process change. The lost-candidate data, the diversity outcomes, and the time their team spends in debate are the levers. Once a hiring manager sees the pattern data on their own funnel, the system stops being a recruiting initiative and starts being theirs.
What about roles where the rubric is hard to write?
Start with three must-haves and three must-nots. Run five candidates against that minimal rubric, then refine from the actual interview behavior. The rubric you ship on day one doesn't need to be perfect. It needs to be specific enough that two interviewers can disagree and point at the same criterion.
How long until the system actually works?
The first five interviews on a new role expose where signal drifts. By twenty interviews in, the panel converges on shared standards. The pattern-detection layer becomes load-bearing around fifty interviews into the same role, when the data is rich enough to flag an interviewer's drift with confidence.
Interviewer bias compounds. So does the system that closes it. Every hire after this one makes the next one fairer, because the rubric is sharper, the panel is more calibrated, and the evidence layer keeps surfacing what private impressions used to bury.
The recruiting teams that hit their goals on hire quality, diversity, and time-to-fill aren't the ones with the most awareness training. They're the ones whose interview behavior is captured, shared, and reviewable.
If you want the system running on your roles, we can show it on your funnel.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.