

I recently used AI agents to optimize a slow React page. The various fixes reduced p95 frame time by ~76%, and I was barely in the loop. The whole exercise made me feel highly AI-used while also barely scratching the surface of what is possible with agents today.
The bottleneck was our AI Sourcing interface, which streams generated messages in real time with attachments, tool calls, nested subagent content, and thinking text. We had put effort into smooth transitions as content animated in and out. The interface is rich. On lower-spec machines, it was also lagging.
What follows is the loop I used to fix it. The interesting part is not the React tricks themselves. It is how little of the implementation I actually did.
The problem
Our AI Sourcing interface streams generated messages in real time. Each message can carry attachments, tool calls, nested content from subagents, thinking text, and more. To keep users oriented in the stream of information, we leaned hard on smooth transitions as content animated in and out.
The interface is rich, and that richness compounded as the application grew. On lower-spec machines, the symptoms were familiar: poor framerates and stuttery animations. The product worked, but it did not feel like the product we wanted to ship.
Animation jank in a streaming interface is the kind of problem that hides until it is too late. The team building the feature does not see it because their machines are fast. The bug report comes in from a customer running a 4-year-old laptop in a hot conference room, and by then the regression has been baked in for weeks.
Agents are best at getting to done when they can verify their own work. Without a benchmark, you are just asking them to guess.”
Putting agents to work
Agents are best at "getting to done" when they can verify their own work. Before asking Opus to fix anything, I needed a way to deterministically test the performance of the page so the agent could tell whether each fix actually helped.
The AI Sourcing page is backed by events, so I asked Cursor's agent (running Claude Opus 4.5) to build a harness that records and replays those events. That gave us a repeatable load: same data, same timing, same everything. Only the code under test changes between runs.
What the harness does
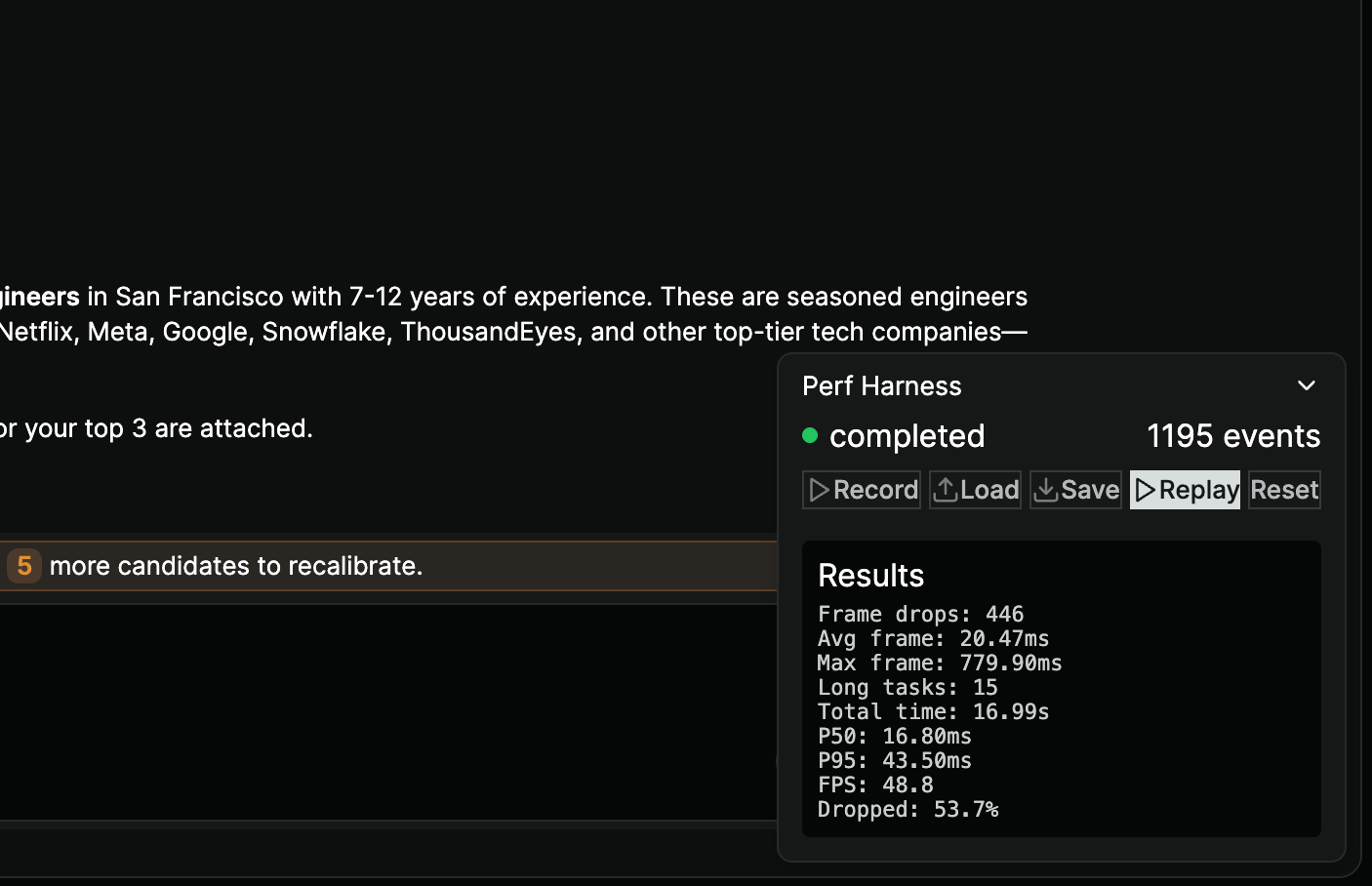
The harness has four jobs. It records every event from a real AI Sourcing chat session. It replays them at 3x speed to compress a full conversation into a tight benchmark window. It measures frame drops, P95 frame time, FPS, and long tasks. And it runs with artificial CPU slowdown to simulate the kind of low-spec machine where the lag showed up in the first place.
I ran the dev server locally and used Cursor's built-in browser to open the app. The agent could navigate to the page, trigger the replay, and read the metrics back. No human in the loop for the measurement step. That single decision (giving the agent a deterministic, agent-callable benchmark) did most of the work that followed.
The loop
I ran the benchmark three times to get a clean baseline, then recorded the result to a markdown file. That markdown file became the spine of the whole project.
From there, I had an agent explore the codebase and produce optimization theories. Large refactors, minor tweaks, deletes, replacements. Everything that looked plausible went into the file as a candidate.
Each implementation experiment was then a separate session. I'd point the agent at the markdown file and have it run a simple loop:
- Choose an idea from the file and implement it.
- Run the benchmark through Cursor's browser.
- Analyze the results and record the findings back to the file.
- Back to step 1.
The markdown file as coordination layer
The markdown file served as coordination between agents. Baseline metrics, optimization theories, and experiment results all lived in one place, accumulating knowledge across sessions. No agent needed to hold the whole project in its head. They just needed to read what had been tried, pick what to try next, and write down what happened.
This pattern functions similarly to the markdown files that help Ralph Wiggum bash loops: a flat, append-only artifact that turns asynchronous agent runs into a coherent project. No clever orchestration, no multi-agent framework, just a file.
What actually worked
The point of this post is less about the specifics of optimizing React and more about how much the shape of software engineering has shifted in the past few months. But for anyone curious about the actual wins, the two changes that mattered most were both familiar problems with familiar fixes. The agent's value was not in the cleverness of the diagnosis. It was in the willingness to try every option, measure each one, and discard the ones that did not work.
Remove Framer Motion layout animations
We had leaned on Framer Motion's layout animations to achieve GPU-enhanced smooth shifting of content. This unfortunately requires siblings to all rerender if their layout animations affect each other, and we were losing the benefits of the React Compiler as a result.
Removing the layout-animation usage cut average frame time by 27%. The animations themselves were nice. The cost of the animations was not.
Zustand instead of React Context
Our messages pipeline produced brand-new references for both the message objects and the message array on every render. React Compiler compares props with ===, so it could not skip rendering message components that had not actually changed.
We could not feasibly change the message pipeline. Instead, we moved the state into Zustand with granular selectors, so message components only re-rendered when their specific data changed. Average frame time dropped another 14%.
Once the agent had analyzed what we should actually implement, I asked it to create a handoff document so a separate agent could implement the change cleanly from scratch in a single, focused session.
What this means for implementation work
A few months ago I would have done most of this work manually. It would have been a chunky effort that consumed my entire day. Last week I did it in a couple of hours, on the side, and I was barely involved.
The gap between "agent finished" and "done done" is rapidly diminishing, to the point that humans barely have to be involved in the implementation of product work at all.
From code review to video review
Last year, when an agent made a PR, I would carefully review the code and functionally verify the change in a local or staging environment. Today our agents open PRs with attached demo videos showing the working feature. I carefully review the video. I skim the code.
The trend on trust in an agent's output is such that I am sure I will not be looking at their PRs at all in the not-too-distant future. The verification surface has moved up the stack. The code is increasingly something an agent produces, an agent reviews, and a human spot-checks for behavior.
The use formula
Give Archimedes a lever long enough and he will move the world.
Give Opus 4.5 a well-defined PRD, a Ralph Wiggum script, and verification steps long enough, and it will build hella software.
Read more on the Metaview Engineering blog.
How we build, ship, and verify AI agents in production at Metaview.
Frequently asked questions
Why does an AI agent need a benchmark to be useful here?
Without a deterministic benchmark, the agent cannot tell whether a given change made the page faster, slower, or had no effect. A repeatable harness that measures frame drops, P95 frame time, FPS, and long tasks gives the agent the verification surface it needs to run an honest experiment loop instead of guessing.
What setup did you use to run the agent and the benchmark together?
Cursor's agent running Claude Opus 4.5, the local dev server, and Cursor's built-in browser. The agent could navigate to the AI Sourcing page, trigger an event replay at 3x speed under artificial CPU slowdown, and read the resulting metrics back. The entire loop, including measurement, runs without a human in the middle.
Why use a markdown file to coordinate agents instead of a framework?
A single shared markdown file is the cheapest possible coordination layer. Baseline metrics, optimization theories, and experiment results all accumulate in one place across sessions. Each agent reads what has already been tried, picks the next idea, runs the benchmark, and writes the result back. No orchestration framework required.
What were the two biggest performance wins on the React page?
Removing Framer Motion layout animations cut average frame time by 27% because sibling components no longer had to rerender on every layout shift, restoring the benefits of the React Compiler. Switching from React Context to Zustand with granular selectors dropped average frame time another 14% by ensuring message components only re-rendered when their specific data actually changed.
How does this change how you review agent-written code?
A year ago, every agent PR meant a careful line-by-line code review plus a manual functional check in a local or staging environment. Today agents open PRs with attached demo videos showing the working feature. The review centers on the video; the code itself gets a skim. The verification surface has moved up the stack, and the trust line keeps moving with it.