

Open the dashboards in most recruiting teams and "hiring velocity" shows up as a single number, usually average time-to-hire, rounded to days. The number moves. Leaders nod. Nothing changes. And while that headline metric keeps rolling, real candidates keep slipping out: according to Metaview's 2026 AI & Hiring Alignment Report - surveying 505 recruiting leaders and hiring managers across North America and EMEA - teams without excellent cross-functional partnerships are 60% more likely to lose qualified candidates to faster-moving competitors. The single number doesn't tell you why.
Velocity is plural. Every stage has its own velocity. Every handoff between stages has its own velocity. The headline number averages all of them together, hiding the one or two that are actually slowing the business down. The biggest leverage in hiring velocity isn't inside the interviews. It's between them, in the dwell time when no one owns the candidate.
This guide breaks hiring velocity into the two layers most dashboards collapse, shows where handoffs leak time, and walks through the capture-and-route layer that compresses them. It ends with a 14-day audit you can run this quarter, without buying anything new.
Why hiring velocity is plural, not singular
Most teams already know their average time-to-hire. They can quote it in the next leadership review. But the number is an artifact: a roll-up that gives stakeholders something to anchor on, not a signal that tells anyone what to do.
Hiring velocity, used well, is the speed at which a candidate moves through your funnel, measured stage by stage. A candidate who waits four days for a screen, two days for an onsite, and six days for a debrief has very different velocity in each stage. Reporting them as "time-to-hire of 12 days" hides which of those three numbers is the one to fix.
The shift to thinking in stages, not totals, is the difference between a metric that decorates a slide and a metric that decides what work gets done. The companies that move fastest don't try to compress the total. They find the slowest stage, fix it, and watch the total move on its own.
That detail matters because it's representative. Most velocity work that pays off is invisible to candidates and only barely visible to the recruiters running it. The handoff that used to take two days now takes two hours. Nobody throws a parade. The funnel just moves.
The two velocities that matter: in-stage and handoff
Hiring velocity has two layers that almost never get reported separately. In-stage velocity is how long the work inside a stage takes: the screen call itself, the onsite block, the take-home review. Handoff velocity is how long the gap between stages takes: the wait for feedback, the wait for a recruiter to chase up, the wait for an HM to approve the next round.
Most teams optimize the first and ignore the second. That's the wrong order. Interview time is mostly fixed: a 30-minute screen is a 30-minute screen. Handoff time is variable and compressible, sometimes by 70 or 80 percent, and it accumulates across every stage. Fix four 24-hour handoffs and you've taken four days out of the cycle without changing a single interview.
There's a quieter cost too. Long handoffs are where partnership friction shows up: only 36% of teams with fair-or-poor recruiter-HM relationships hit their goals last year, compared with 79% of teams with excellent relationships and high alignment. Slow handoffs aren't just slow. They're a tell.
How to measure handoff velocity (the part dashboards miss)
Most hiring dashboards measure time-in-stage and call it a day. To measure handoff velocity, you need three things you almost certainly don't track today: the timestamp when an interview ended, the timestamp when feedback was submitted, and the timestamp when the next stage was scheduled.
The arithmetic is trivial. The reason nobody does it is that all three timestamps live in different systems, often partially missing, and the work to stitch them together is exactly the kind of recruiter ops project that gets deprioritized for the third quarter running.
You don't need a custom integration to start. For the next 30 closed reqs, pull those three timestamps by hand into a spreadsheet. The median dwell time per handoff is your baseline. The worst-performing handoff is your target. Both numbers will surprise you.
- Feedback lag is invisible until a candidate ghosts.
- Time-to-hire moves with no clear reason.
- Recruiters chase feedback by Slack DM, three days running.
- HMs are blamed for slow decisions they never knew were slow.
- The same stage stays the bottleneck for years.
- Every handoff has a timestamp, owner, and SLA.
- Per-stage dwell time shows up beside time-in-stage.
- Slow handoffs trigger a nudge before they cost a candidate.
- HMs see what their average handoff actually is.
- Bottlenecks move, because you can see them move.
Where handoffs break: 5 dwell-time leaks
Five places dwell time accumulates in a typical mid-market funnel. Some are obvious; the obvious ones aren't always the biggest.
- Screen-to-onsite. The longest gap most teams accept without noticing. Two days for a recruiter recap, three days for HM review, four days for an availability poll. The fix is usually structural, not effortful.
- Onsite debrief. Often a 48-hour window in policy, a 96-hour reality in practice. The interviews are done, the signal is there, but nobody has written it up in shareable form.
- HM-to-recruiter feedback. The single most-complained-about handoff in recruiting. Solved partially by 24-hour SLAs, fully by removing the writing burden so feedback writes itself from the interview.
- Recruiter-to-HM intake. The mirror of the previous one. Recruiter has a strong candidate, HM is in product reviews, the candidate cools. Same fix: send the HM a structured summary before they need it.
- Offer prep. Comp, level, references, sign-off chain. Usually the longest handoff in the whole funnel and almost never measured, because it sits outside the part of the ATS recruiters report on.
The capture-and-route layer: how interview intelligence compresses handoffs
Compressing handoffs isn't a culture problem. It's a capture-and-route problem. The signal is already in the interview: the assessment, the concerns, the next-step suggestion. The reason the handoff is slow is that the signal has to be re-encoded by hand after the call, by someone who's already done four interviews that day.
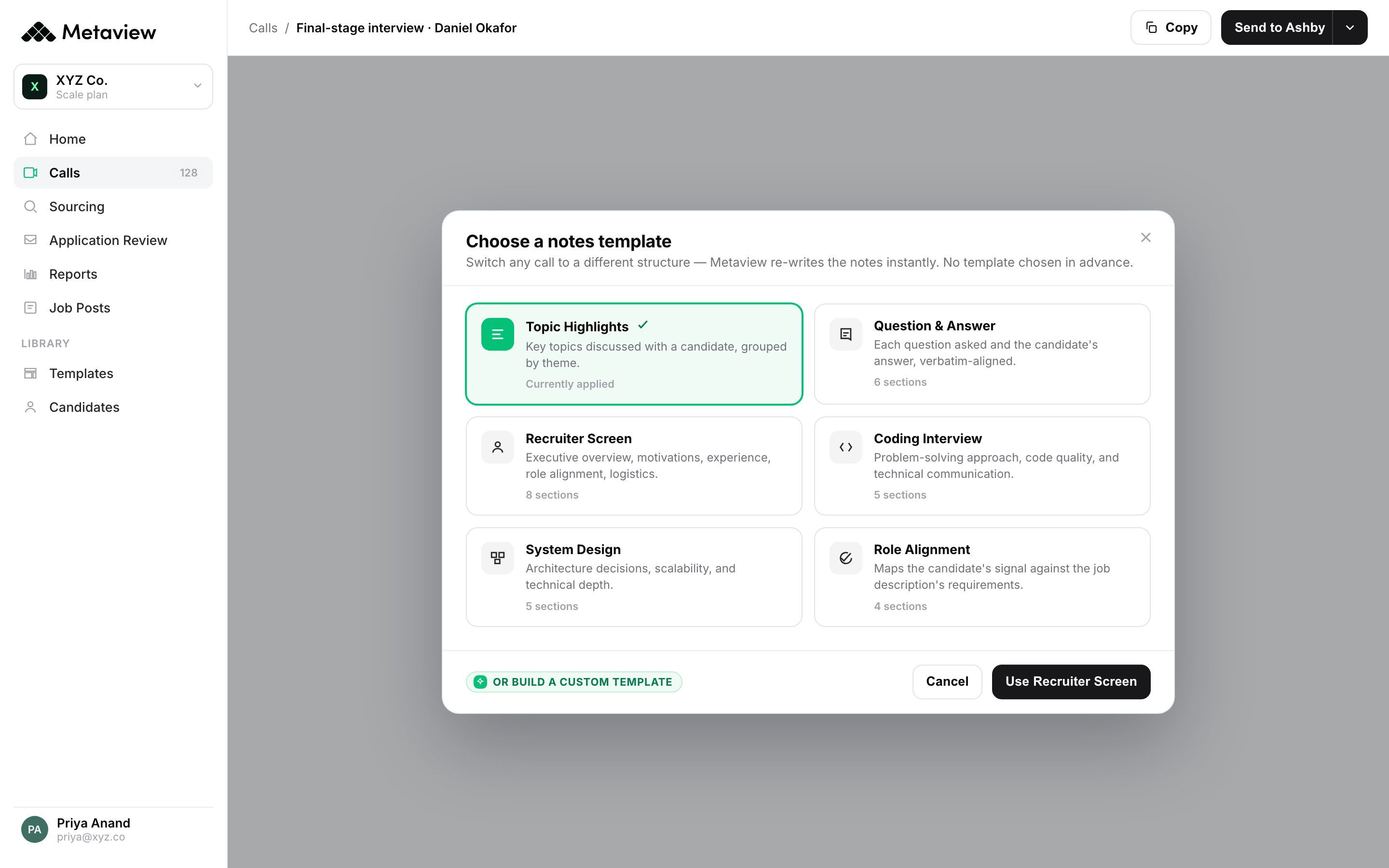
The fix is to capture the signal in structured form as the conversation happens, then route it (to the scorecard, to the ATS, to the next interviewer) without anyone touching it again. Interview intelligence does exactly that. When AI Notes generate a structured summary in the candidate's record before the HM has closed their laptop, the "wait for feedback" handoff stops existing.
What's changed in 2026 is that the structured capture is no longer a separate workflow. Metaview's scorecard autofill now uses the interviewer's default AI Notes template as additional context, so the scorecard fields are populated from the right transcript moments without anyone copy-pasting. The handoff isn't faster because someone is hustling harder. It's faster because nobody is doing the manual step.
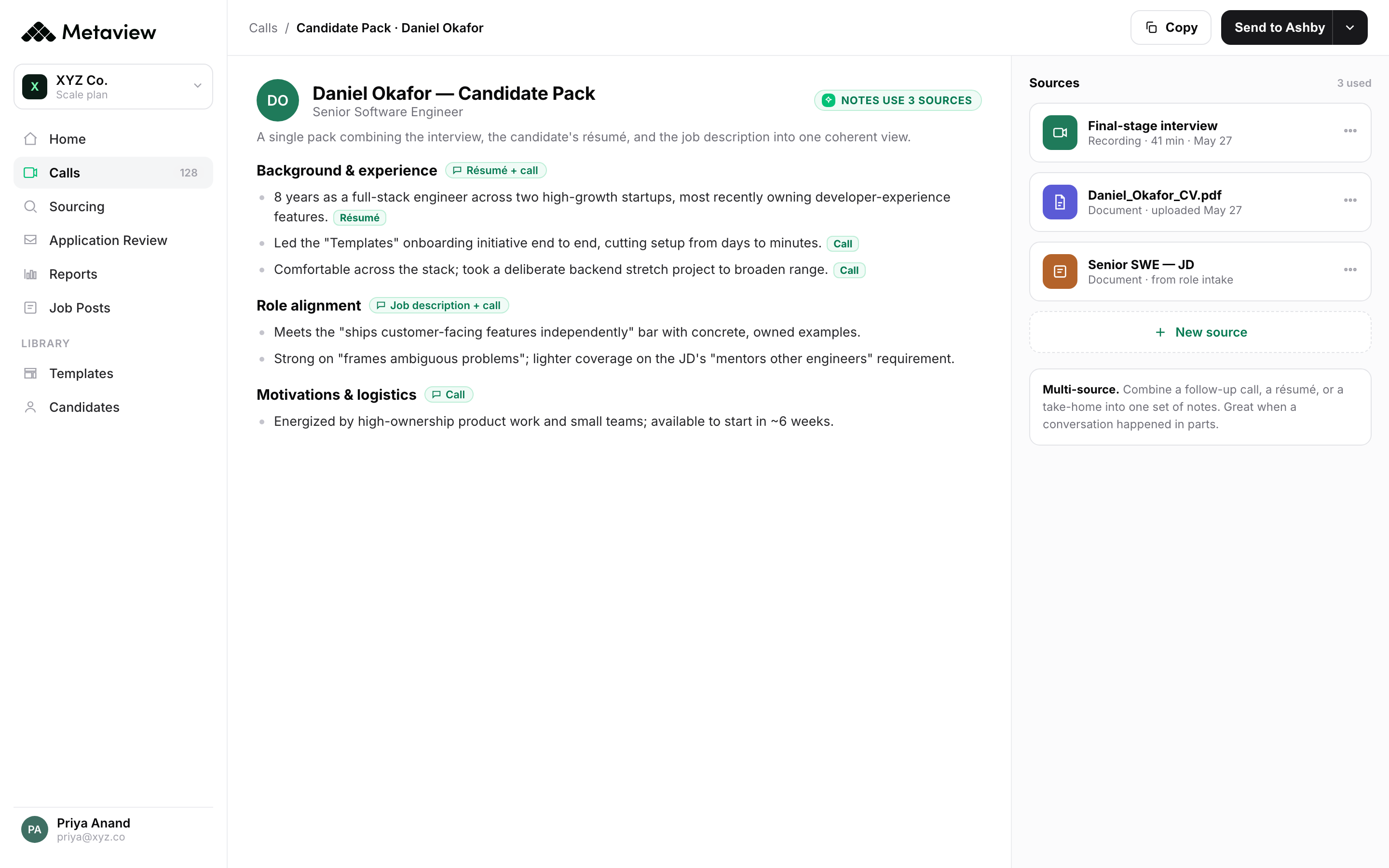
- 1Cross-panel summary stitched the moment the last interview ends, so the next handoff starts with a structured packet.
- 2Per-stage signal already extracted, so no one has to re-watch a recording to write the next-step recommendation.
- 3Action items are pre-routed by panel, which is what turns offer prep from a 4-day handoff into a same-day one.
I've been using Metaview for 30 days now, and the results are incredible. No more manual note-taking during candidate calls, it's all automated. I used to struggle to keep up with evaluations, but now it's a breeze. I've gone from handling 6 pre-screens to over 10 a day, talking about efficiency!”
What changes when handoffs compress: throughput, quality, and HM trust
Compress handoffs and three things change in order. First, throughput. The same recruiting team starts running more candidates per week because no one is waiting on anyone. Second, quality. Faster handoffs mean candidates haven't gone cold by debrief, so the debrief is on actual recall, not reconstructed memory. Third, HM trust. When an HM sees that feedback they submitted Wednesday at 5pm is in the ATS at 6pm with the next stage scheduled by Thursday morning, the recruiting team stops being the people who chase and starts being the people who deliver.
The throughput change is the one most teams pitch internally; the trust change is the one that holds the gains. A six-month run of compressed handoffs is what gets recruiting moved from a cost-center conversation to a planning-partner conversation.
A 14-day handoff audit you can run this quarter
Most velocity improvements don't need a new system. They need 14 days of attention. Here's the audit, week by week.
- Days 1-2: Pull the last 30 closed reqs. For each candidate, log the timestamp of the last interview, the timestamp of submitted feedback, and the timestamp of the next-stage hold. Median dwell time per stage is your baseline.
- Days 3-5: Identify the worst-performing handoff (it's usually screen-to-onsite or HM debrief). For that handoff only, set a 24-hour SLA in writing. Tell the HMs. Don't change anything else.
- Days 6-9: For new candidates entering that stage, send the HM the structured AI summary at the same time as the meeting invite. Cut the writing burden in half. Track which HMs hit the SLA and which don't.
- Days 10-12: Loop the data back to the HM in your weekly sync. Show them the dwell-time chart, with their stage highlighted. Don't moralize. The data does the work.
- Days 13-14: Pull dwell time for that handoff again. If it's down 30% or more (most are), pick the next worst handoff and repeat. If it isn't, the problem isn't the SLA, it's the capture layer, and you have a clear next move.
Over the past year, we've saved over 1,000 hours for our interviewers and recruiting team. Beyond that, Metaview has allowed me as a talent leader to gain insights across meta themes like compensation or common candidate questions. It lets me be really proactive in my approach, versus reactive with problems that might come up.”
 Metaview
MetaviewBring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Frequently asked questions
Is hiring velocity the same as time-to-hire?
No. Time-to-hire is one rolled-up number; hiring velocity is a vector across every stage and every handoff. Tracking only the rollup hides the one or two handoffs that are actually slowing you down.
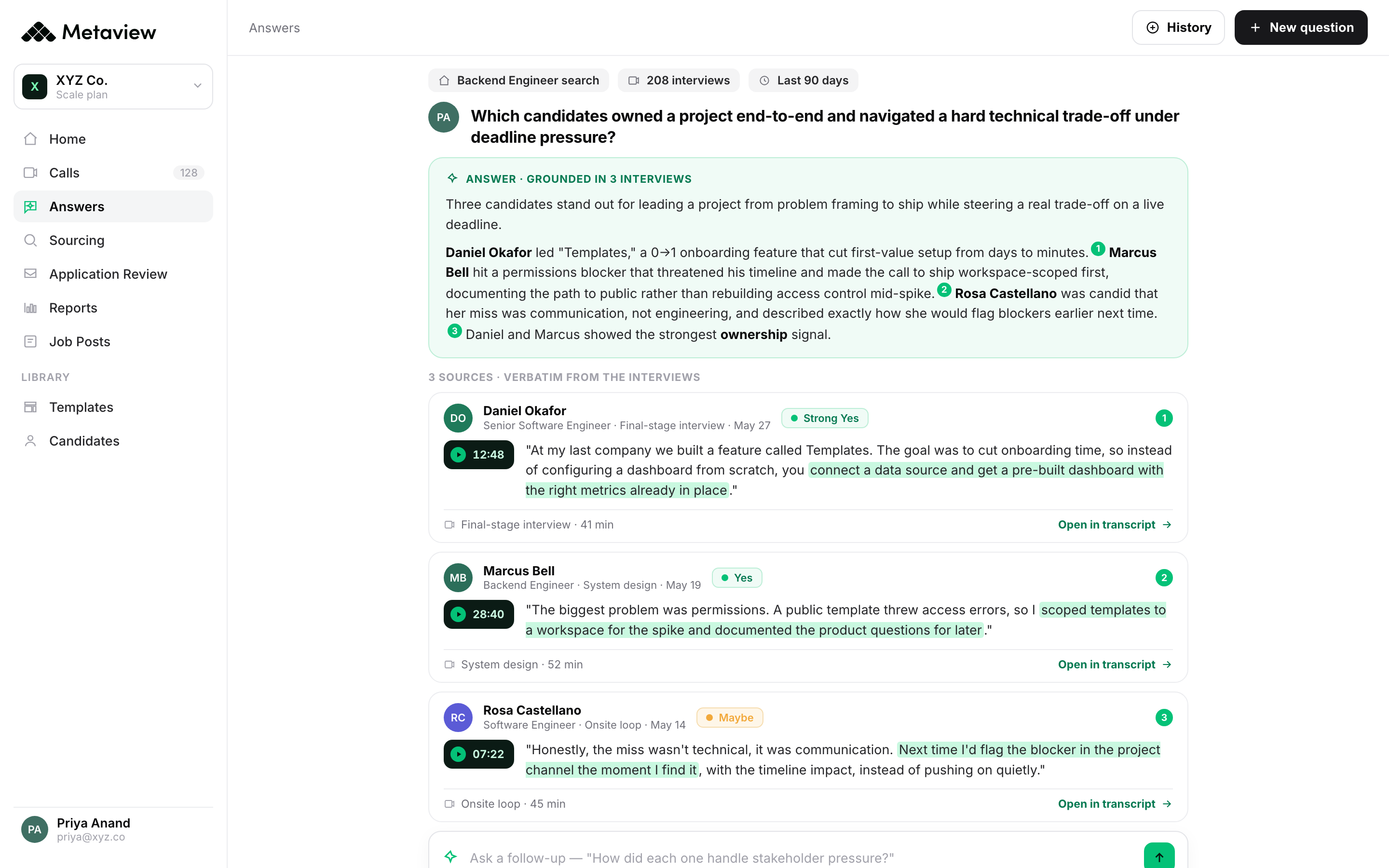
Where is the biggest leverage in hiring velocity?
In the handoffs, not the interviews. Interview time is mostly fixed; handoff time (the wait between stages) is variable and compressible, sometimes by 70 to 80%, and it accumulates across every stage of the funnel.
Can improving hiring velocity hurt candidate quality?
Not if you compress handoffs rather than interviews. Quality drops when you skip evaluations or shorten signal capture. Quality goes up when you compress dwell time, because debriefs happen on fresh recall instead of reconstructed memory.
How do I measure handoff velocity if my ATS doesn't track it?
You need three timestamps per candidate: when the interview ended, when feedback was submitted, and when the next stage was scheduled. Most teams can pull this manually for the last 30 closed reqs in a day, which is enough to find the worst handoff.
Who should own hiring velocity at the org level?
Recruiting owns the metric, but the fix requires shared accountability with hiring managers. A 24-hour feedback SLA, written down and shown on a weekly chart, does more for handoff velocity than any process redesign.