

Most TA teams in 2026 don’t have an AI agent problem. They have an AI agent stack problem. The intake call gets summarized by one tool. The sourcing agent finds candidates without ever reading the intake. The screening agent generates a fit score, but never sees what the recruiter heard on the phone. The notetaker produces a transcript that the reporting layer can’t parse. Six logos on a slide, zero shared memory between them.
That fragmentation is now showing up in the data. According to Metaview’s 2026 AI & Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, 85% of companies exceeding their hiring goals use AI in hiring, and teams that put AI at the core of hiring are 3.8x more likely to rate their cross-functional relationship as excellent. The teams seeing those gains aren’t the ones running the most agents. They’re the ones running agents on top of a single shared layer of interview signal.
This article walks through the seven agent types most TA leaders are already evaluating, what specifically breaks when each one runs in isolation, and the four shared-memory jobs that replace them when the interview transcript corpus becomes the connective tissue. The reframe is the difference between buying seven point solutions and installing one architecture.
The seven AI recruiting agents most TA teams already have
Walk a TA leader through their AI roadmap in 2026 and the same seven agent categories come up almost every time: sourcing (the agent that searches LinkedIn, ATS, and the open web for candidates); screening (the agent that scores inbound applications against an ICP); notetaking (the agent that captures interviews and produces structured notes); reporting (the agent that builds dashboards from interview and pipeline data); JD writing (the agent that drafts and rewrites job descriptions); interviewer training (the agent that flags weak questioning patterns); and workflow automation (the agent that moves candidates between ATS stages without recruiter clicks).
Each one in isolation is a reasonable purchase. None of them is the actual unlock. The unlock is the part of the stack that ties them together, and that part is almost never on the procurement slide.
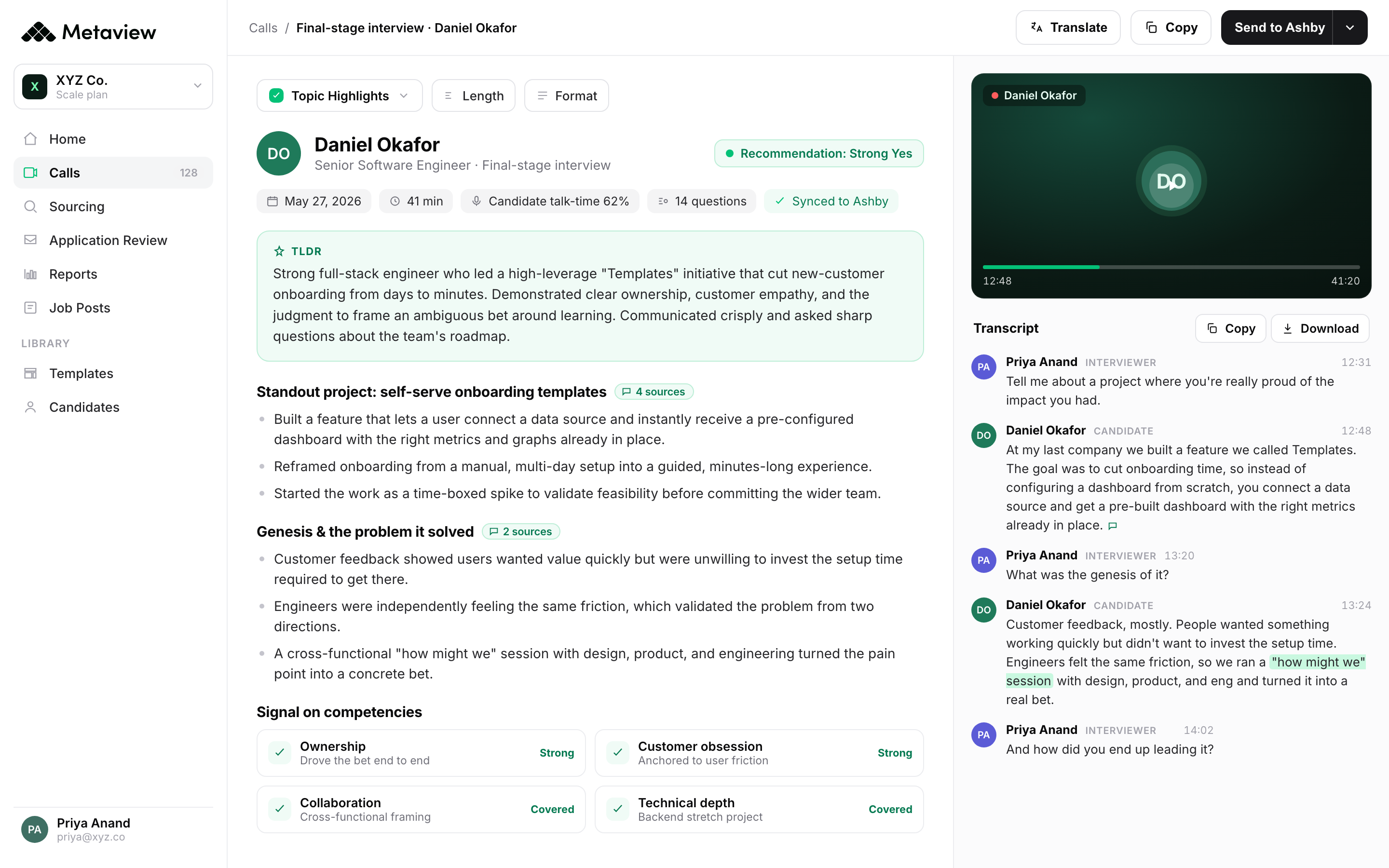
Most TA functions already run at least three of these seven, often without realising it. Application Review screens inbound at the door; an AI notetaker captures the screening call; an outbound sourcing agent runs in the background. According to Metaview’s 2026 AI & Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, 85% of companies exceeding their hiring goals use AI in hiring. The header number gets misread as ‘AI works.’ The stronger read is that the teams winning with AI are the ones who got the integration story right, not just the agent count.
For solo recruiters especially, this creates what I call having ‘a team working for me.’ The tool runs continuously in the background, sourcing candidates even when I’m focused on other tasks. By the next day, new profiles are waiting for review.”
The memory problem: why those seven agents underperform in isolation
The seven agents are real, the categories are stable, and the products in each category are getting good. What stays broken is the handoff between them. Every boundary in the recruiting funnel is a place where context dies. Without a shared memory layer, each agent re-derives the same context from scratch and gets it wrong in a slightly different way than the last one. Four specific handoffs fail.
Intake to sourcing
The hiring manager spends thirty minutes describing what good looks like for this role. Then the sourcing agent fires on the job spec the recruiter wrote a week ago, before the kickoff. The agent doesn’t know about the two must-haves added at intake or the three reject reasons the hiring manager called out. The first shortlist is wrong in a way only the kickoff transcript could have prevented.
Screen to debrief
The recruiter screens the candidate and writes a one-line summary. The hiring manager interviews the same candidate and writes their own one-line summary. By the debrief, the two notes are about two different candidates, because the captured rationale never left the recruiter’s head and never entered the interviewer’s context. The notetaker captured the conversation, but the screening agent didn’t read it.
Debrief to reports
Reports get built from whatever fields the recruiter remembered to fill in. The reporting agent has access to scorecard outcomes but not the substance of why each interviewer voted the way they did. Quality of hire becomes a number that arrives six months too late to change anything about the next requisition.
Reports to the next intake
The single most expensive missing handoff: nothing the reporting agent learns about which interviews predicted strong hires actually changes how the sourcing agent runs the next search. Every requisition starts from scratch. The org keeps paying the calibration tax over and over because no shared layer accumulates the answers.
From seven agents to four shared-memory jobs
The four-job reframe doesn’t add agents. It collapses the seven existing categories into four operational beats that read from and write to one record: the structured interview transcript. The agents stay; the architecture changes. Once Capture, Compare, Compose, and Close all share the same underlying artifact, every additional agent inherits the context the previous one produced.
Read ‘Capture’ as the notetaker working through every conversation: intake, screen, interview, debrief. Read ‘Compare’ as sourcing and screening agents reading the captured intake before they score. Read ‘Compose’ as the scorecards, debrief docs, and ATS writebacks that draft from the same transcript corpus rather than from scratch. Read ‘Close’ as the reporting and calibration layer that queries the same memory the agents read from at the start. Same artifact, four consumers.
The contrast: stacked specialists vs. shared interview memory
The fastest way to see why the four-job reframe matters is the gradient itself: what actually changes as you add each agent on top of the prior layer, and what changes the moment you switch from stacking specialists to running them on a shared memory layer. The 5-column gradient below holds the dimension constant across the row and moves left to right from manual through cumulative agent additions to the shared-memory end state.
| Dimension | Manual | Notetaker only | + Sourcing & screening agents | + Shared interview memory |
|---|---|---|---|---|
| Intake quality | Recruiter writes from memory after the call. | Transcript captured; no structured intake doc. | Sourcing agent fires before intake is summarized; runs on the job spec only. | Intake summary, must-haves, and reject reasons travel from kickoff into every downstream agent. |
| Sourcing relevance | Boolean search; senior judgement substitutes for context. | No improvement; sourcing happens outside the meeting layer. | Sourcing agent scores by ICP keywords, with no feedback loop from screens. | Sourcing agent reads transcript summaries of intake and prior screens to calibrate the ICP. |
| Screen consistency | Each recruiter screens to a different bar. | Notes captured per call, but the bar stays implicit. | Screening agent applies a static scorecard, divorced from how the recruiter heard the answer. | Screening agent inherits the scorecard plus the recruiter’s captured rationale on prior screens. |
| Debrief decision speed | Reconciliation between recruiter, hiring manager, and panel happens in a meeting that often slips. | Notes shared, but each interviewer still rereads everything before the debrief. | Multi-tool exports stitched together by the recruiter under time pressure. | Multi-source summary auto-compiles the panel’s conclusions against the original scorecard. |
| Reporting fidelity | Reports built off spreadsheets of what people said they did. | Notes feed reporting, but field mappings are recruiter-set. | Reporting agent operates on whatever export shape each tool produces. | Reporting agent queries the same transcript corpus the screening and sourcing agents already use. |
| Post-hire learning loop | Calibration meetings are anecdotal; lessons don’t persist. | Transcripts exist, but no one reads them six months later. | Each agent forgets its own outputs after every cycle. | Calibration data accrues in the same memory layer that the next intake, sourcing run, and screen will read from. |
Where the shared memory lives: the interview transcript corpus
The architecture question is concrete. What artifact is the memory layer? The answer Metaview has converged on, after years of running it across thousands of customer interviews, is the structured interview transcript itself. Each conversation produces an artifact that captures who said what, mapped to the scorecard the recruiter built. Every downstream agent reads from that artifact rather than from one another’s outputs. The corpus is the contract.
That choice has two architectural consequences worth flagging. First, every additional agent gets cheaper rather than more expensive to add, because the integration surface is one artifact, not N×N tool-to-tool plumbing. Second, the memory layer becomes the place the calibration data accrues: the next intake summary reads what the prior panel concluded, the next screen reads what last quarter’s strongest interviews had in common, and the reports query the same substrate the agents are writing to.
Below, Siadhal Magos walks WeAreDevelopers through the build-vs-buy dilemma for AI tools, why the rise of agents makes the human ability to orchestrate more valuable than ever, and the build pattern that turned interview transcripts into the connective tissue for everything downstream.
Metaview doesn’t just save time, it makes our entire process smarter, more insightful, and ultimately more human.”
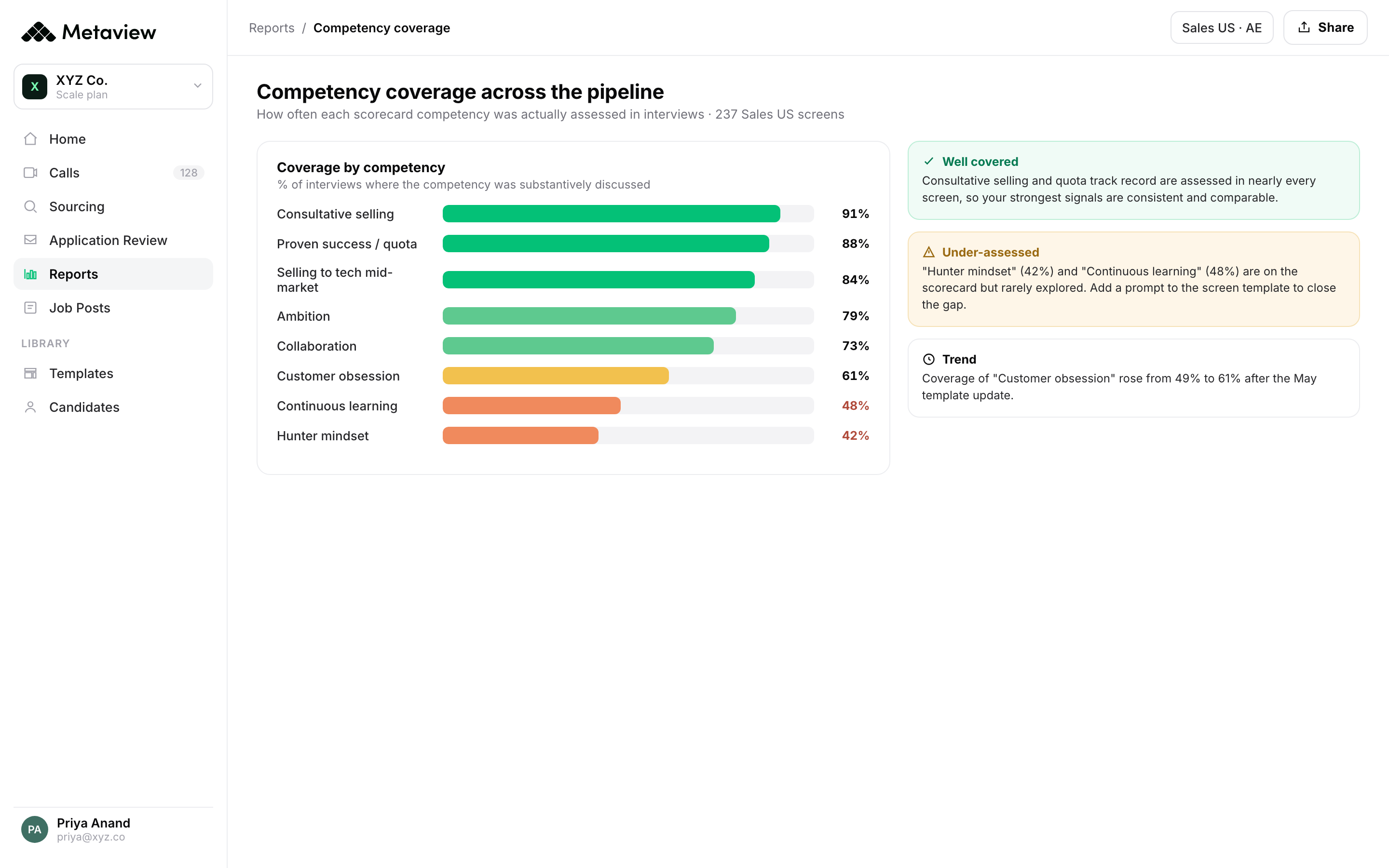
One canonical record of every conversation: intake, screen, interview, debrief. Live audio, structured against your scorecard, with custom note templates per interview type.
The sourcing agent and the screening agent read the same captured intake. Candidate fit is scored against the rationale the recruiter just heard on the phone, not a static ICP keyword list.
Scorecards, debrief docs, hiring manager updates, and ATS field writebacks all draft from the same transcript corpus. The recruiter edits one canonical artifact, not six.
Reports, dashboards, and calibration loops query the same memory layer the agents read from at the start. Quality of hire becomes a closed-loop signal, not an after-the-fact report.
A 30-day migration plan: from agent sprawl to shared memory
Three weeks of work, one week of measurement. The plan below is calibrated for a TA function that already runs two or three AI agents in isolation today and wants to install the connective tissue without ripping out existing point tools. It works because the new layer is additive: you turn on Capture first, route the existing agents to read from it, then evaluate which of the seven specialist agents are still earning their seat.
- Days 1-5 · Install the Capture layer. Turn on Metaview across every interview type (intake, screen, panel, debrief). Map note templates to the existing scorecard. Confirm ATS writeback for at least one role family.
- Days 6-12 · Route existing agents to read from Capture. If sourcing runs in Gem, SmartRecruiters, Ashby, or Greenhouse, point it at the captured intake summary so the shortlist reflects what the hiring manager actually asked for at kickoff.
- Days 13-19 · Turn on Compose. Auto-draft scorecards, debrief docs, and hiring-manager updates from the same transcript. Stop the parallel-document tax: one canonical artifact, edited once.
- Days 20-26 · Turn on Compare and Close. Application Review reads the captured intake before scoring inbound. Reports query the same transcript corpus the agents are writing to. The loop is closed.
- Days 27-30 · Audit which specialist agents are still earning their seat. Several will turn out to be redundant once the shared layer exists. Cancel them. The remaining stack will be smaller, cheaper, and produce more aligned hires than the seven you started with.
 Metaview Technologies
Metaview TechnologiesBring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.