

Every talent calibration deck has the same problem. The data inside it is already 90 days old. By the time the slide opens, the panel has shipped a hiring decision the deck can no longer change. The committee debates ratings on candidates who already accepted offers, declined offers, or moved on. The fix isn't a better deck. The fix is compressing the loop so calibration shapes the interview, not just the post-mortem of it.
Most TA leaders inherit calibration as a meeting. Quarterly, candle-lit, with a spreadsheet, ratings recalibrated by committee, and an action list that no one re-opens. Useful as a ritual, almost never useful as a control system. The teams pulling ahead in 2026 treat calibration as a verb: what every panel does together at the moment of capture, written down once and read by everyone.
This guide is a 2026 talent calibration playbook for TA leaders running headcount in a compressed market. It walks through what calibration actually means when it works, the four ways quarterly calibration breaks, where the loop can be compressed, the 4-card mechanic that makes it live, a 30-day install plan, and the FAQ at the bottom for the questions everyone asks first.
What "calibration" actually means when it works
Talent calibration is the process of getting every interviewer, hiring manager, and decision-maker evaluating the same role against the same bar with the same evidence. When it works, two recruiters looking at the same candidate write nearly the same scorecard. Two panelists watching the same interview pull the same signal. Two cross-functional reviewers on the same loop agree on whether the role is for engineering capability, judgment, or trajectory before the interview starts.
Most companies confuse calibration with a calibration meeting. The meeting is one venue for calibration. The work itself is happening, or failing to happen, on every single interview during the loop. Calibration is a verb describing how a hiring decision converges, not a noun describing a slide deck.
Said differently: calibration is whether two interviewers, working independently, can write the same scorecard. If they can, the loop is calibrated. If they can't, every interview is leaking signal, and no quarterly review will get it back.
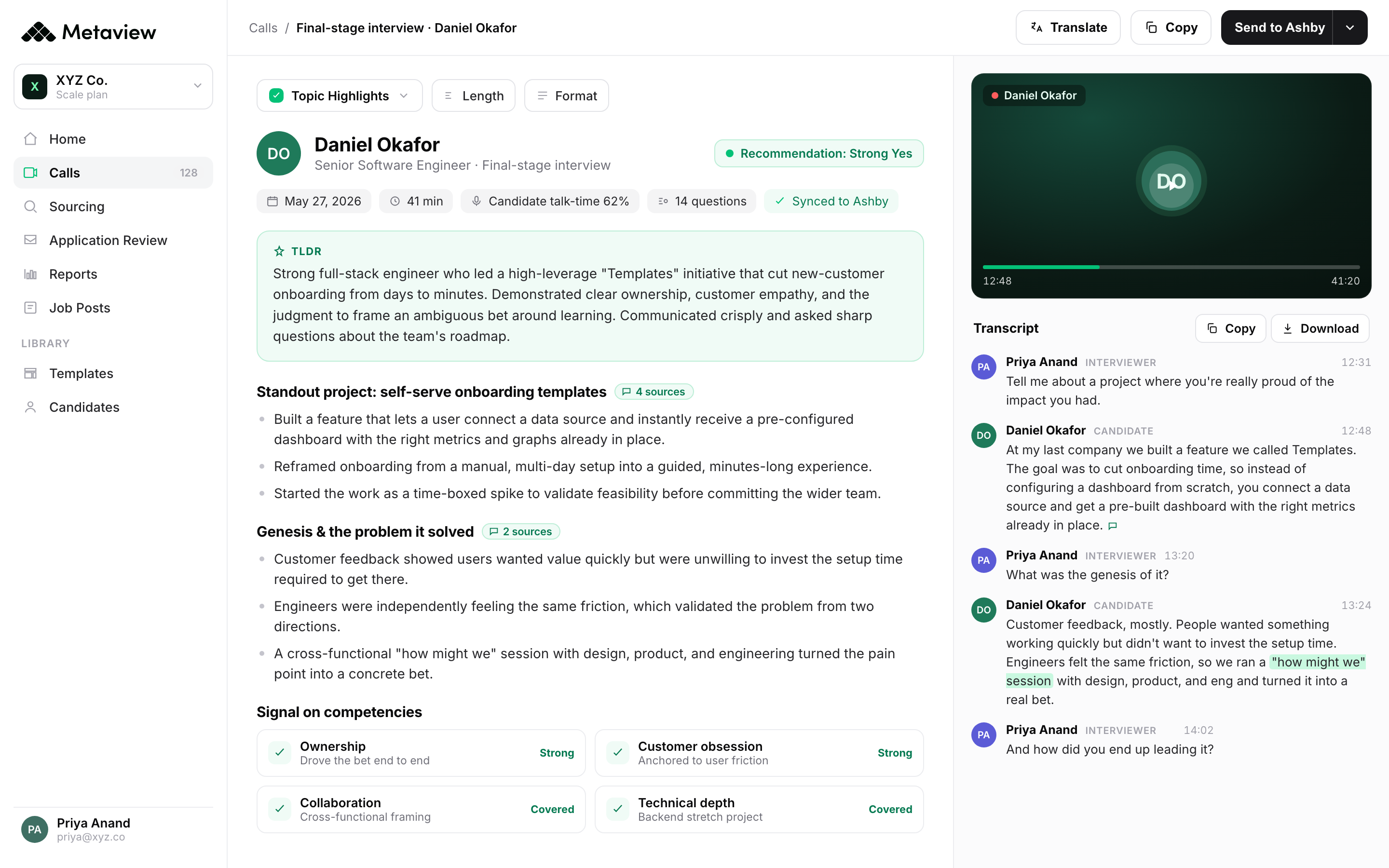
The reason this matters at scale is in the data. According to Metaview's 2026 AI & Hiring Alignment Report - surveying 505 recruiting leaders and hiring managers across North America and EMEA, fielded with Cint - alignment at kickoff is the single largest predictor of whether the loop downstream is recoverable. When AI is core to hiring, 68% of searches start aligned. When it isn't, only 49% do. The 19-point alignment gap is the gap live calibration is built to close.
My intake is daunting, an hour-or-two form. I don't even schedule the kickoff until they've returned it within 24 hours. I want them to fill it out on a Saturday morning with a fresh cup of coffee, not when they're getting a thousand Slacks. When founders understand the why, they do it.”
The four breaking points where calibration becomes theater
Quarterly calibration breaks in four predictable ways. Every TA leader who has run the meeting for more than a year recognizes at least two. The four below cover the failure modes that show up on every team running calibration as an episodic ritual rather than a continuous practice.
Stale data
The data inside a quarterly calibration deck is, by construction, three months old. The candidates being calibrated have already moved through the loop, into onboarding, or out the door. The discussion is informative, but rarely actionable. A finding in the deck that interviewer Alex consistently over-indexes on confidence over content cannot retroactively change the candidates Alex interviewed last quarter. Without a way to feed the finding back into this week's interviews, the deck stays an autopsy.
Recency bias
Three months of interview impressions cannot be reconstructed from memory. By the time the meeting starts, every panelist remembers the last 3-4 candidates clearly and almost nothing before that. The discussion drifts toward the candidates panelists can still see in their heads, which makes the calibration meeting a debrief of the recent rather than a calibration of the whole loop. Recency dictates the agenda, not signal.
Asymmetric memory
Different panelists remember different fragments of the same interview. A hiring manager remembers the architecture question. The recruiter remembers the comp conversation at the end. The bar-raiser remembers the candidate stumbling on a follow-up. The panel argues with each other from non-overlapping snippets of the same hour. Without a shared, replayable record, every calibration discussion is each panelist's slice of the elephant.
Decision drift
Calibration meetings frequently end with a ratings recalibration that the next week's panel doesn't read, doesn't internalize, or actively disagrees with. The team agrees in the room that a senior IC needs to score 3+ on system design to move forward, and then approves someone at 2.5 the following Tuesday. Without a mechanism that surfaces last week's calibration at the moment of next week's decision, calibration decisions decay between meetings.
Where the calibration loop actually compresses
There are exactly four moments in the interview loop where calibration can be compressed. Each one is a different intervention. Together they collapse the 90-day calibration cadence into a per-interview rhythm.
The first compression is at kickoff. If the intake call is captured verbatim and turned into a structured rubric the same day, every interviewer downstream is reading the hiring manager's own words instead of the recruiter's two-sentence summary. The rubric becomes the calibration artifact for the entire loop. Calibration at kickoff is the highest-leverage moment because every subsequent interview inherits its quality.
The second compression is during the interview itself. If the conversation is captured and mapped to the rubric in real time, the panelist sees the questions they intended to assess, the moments where the candidate addressed them, and the moments where they drifted. Calibration here is per-question, per-competency, per-interview - not a ratings rollup at the end.
The third compression is between panelists. The hardest-to-fix asymmetric memory problem disappears the moment every panelist can read a 2-minute summary of every other panelist's interview. The discussion moves from "what do you remember" to "what do you make of this" - which is the discussion calibration was always supposed to be.
The fourth compression is at decision. If the scorecard pushes back into the ATS as the artifact of record, the next role with the same competency stack inherits the calibration. The calibration loop stops being something the team has to re-establish on every new req.
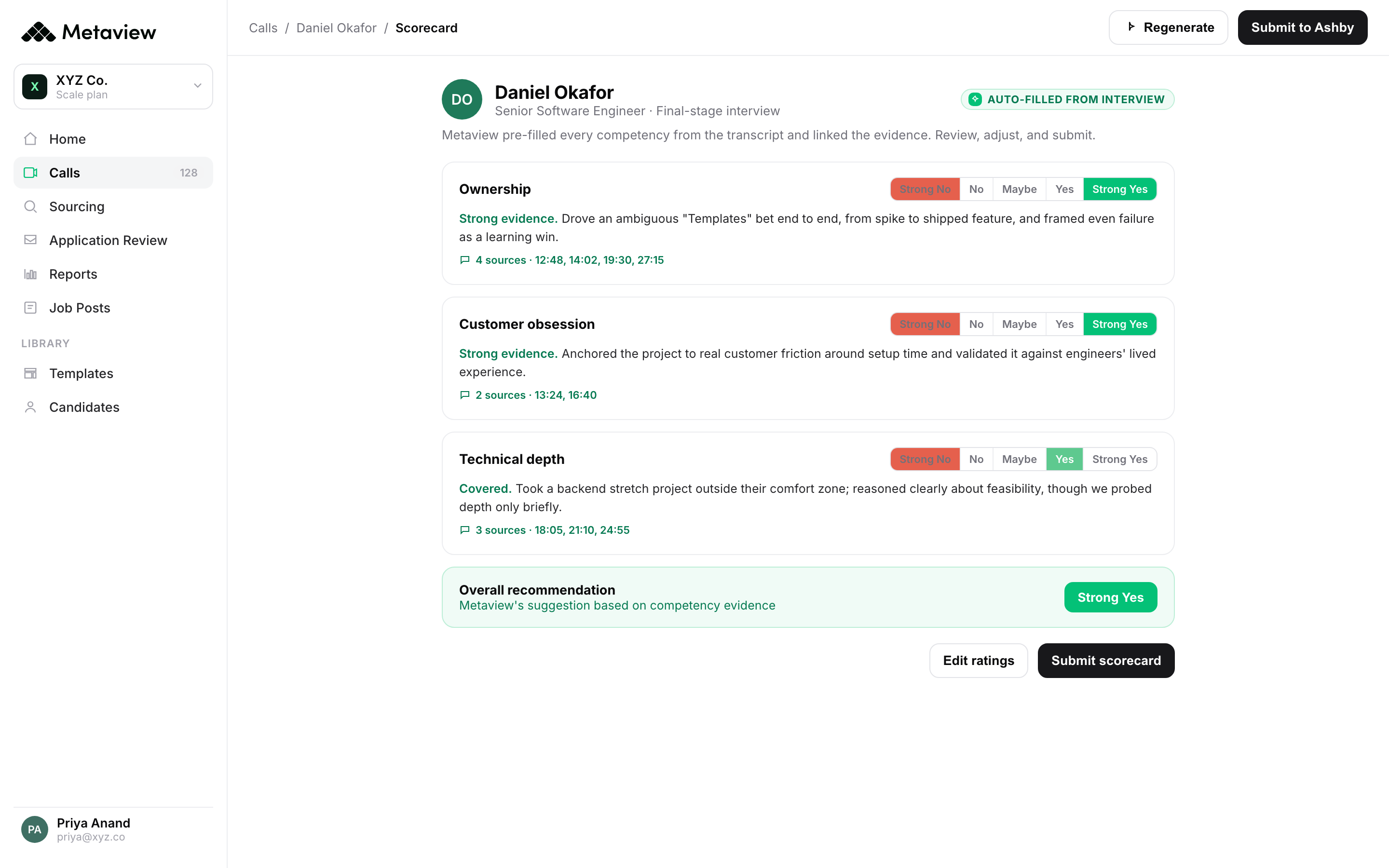
Without and with: quarterly vs live calibration
The clearest way to see what compressing the loop changes is to put the two operating models side by side. The left column is calibration as a quarterly meeting. The right is calibration as a per-interview rhythm. The same headcount goal, the same competency stack, the same panel - just two different operating cadences. The contrast is what actually drives outcome.
- Calibration data is 90 days old when the meeting opens.
- Panelists argue from non-overlapping memory of the same interview.
- Last quarter's calibration decisions don't reach next week's panel.
- Every new req re-establishes calibration from scratch.
- Hiring manager intake survives as a recruiter's two-sentence summary.
- Calibration shapes the next interview, not the post-mortem of it.
- Every panelist reads a 2-minute summary of every other panelist's interview.
- Last interview's rubric drift surfaces at the moment of the next decision.
- Calibration pushes into the ATS so every future req inherits it.
- The intake call itself is the calibration artifact for the loop.
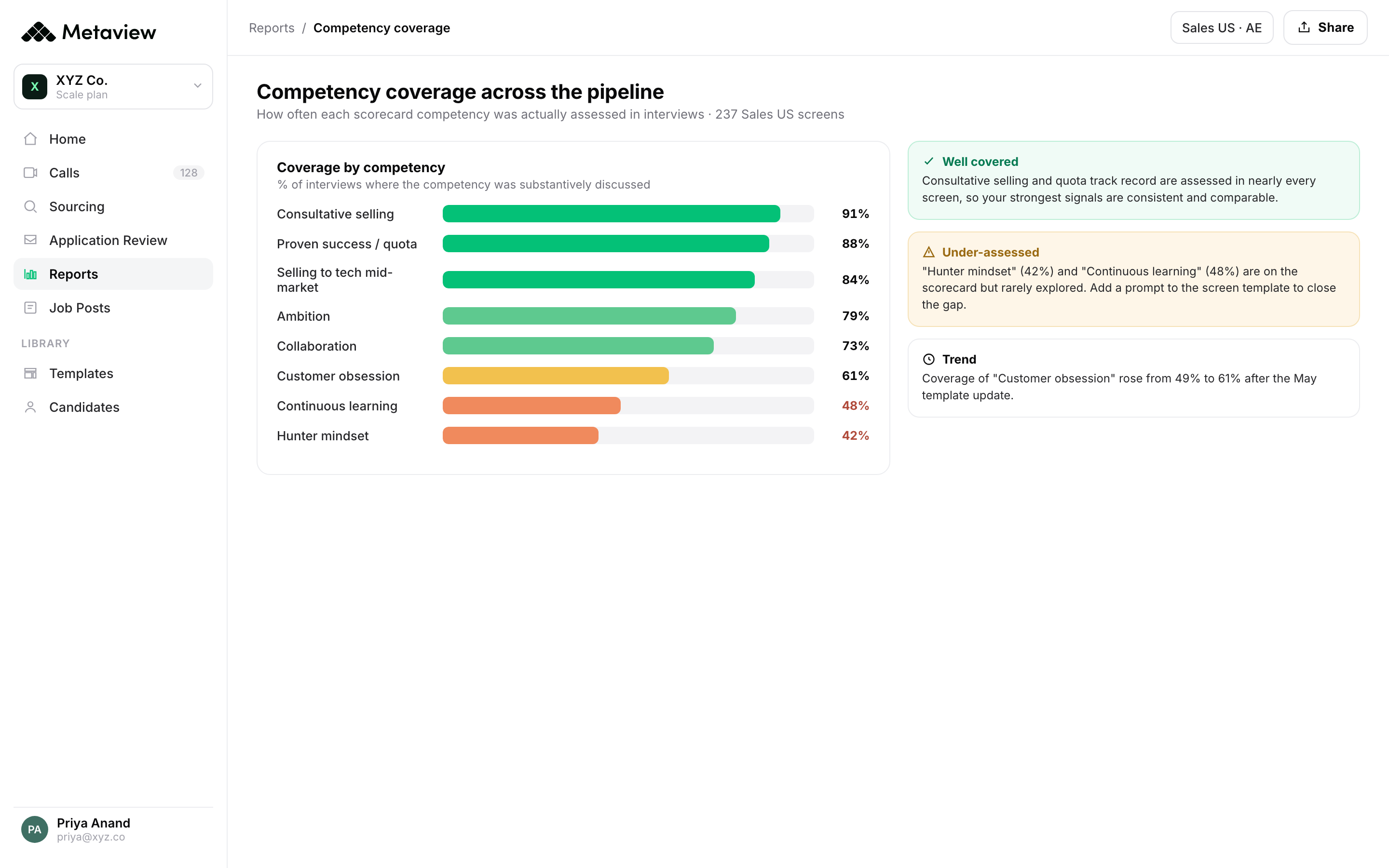
The four-card mechanic that makes calibration live
Translating the four compression points into a working mechanic takes four product surfaces. Each one is a different layer in the loop. Together they create the live-calibration operating model the rest of this guide assumes.
Notetaker captures the interview verbatim and joins the call without a bot in the room. The first calibration artifact is the conversation itself, captured the moment it happens.
AI Notes maps the captured conversation to the rubric and fills the scorecard against your competencies. Calibration is per-question, per-competency, per-interview, not a ratings rollup at the end.
Every panelist reads a 2-minute structured summary of every other panelist's interview before going in. Asymmetric memory disappears because the panel is reading the same record.
The completed scorecard pushes into Ashby, Greenhouse, Lever, Workable, SmartRecruiters, Gem, JobAdder, or Teamtailor as the artifact of record. The next req with the same competency stack inherits the calibration.
On the 10x Recruiting podcast, Amber Weinberg (Aperture Partners) argues that at the executive layer, the scorecard alone stops carrying calibration. It needs back-channel references, cultural-wiring assessment, and a 6-month onboarding loop to hold. Worth listening to whether you run an exec loop or not, because the principle is the same lower in the stack: calibration is a system, not a form.
Over the past year, we've saved over 1,000 hours for our interviewers and recruiting team. Beyond that, Metaview has allowed me as a talent leader to gain insights across meta themes like compensation or common candidate questions. It lets me be really proactive in my approach, versus reactive with problems that might come up.”
 Siadhal Magos
Siadhal MagosThe 30-day install plan
Adopting live calibration doesn't need a 6-month transformation program. The install plan below is four weeks. Most TA teams can complete it inside one hiring cycle. The aim is to move calibration from a quarterly meeting to a per-interview rhythm without disrupting the loop that's already running.
- Week 1. Pick three open reqs as the pilot. Set up the capture layer on every interview in those reqs - intake, screening, technical, debrief. Don't change the questions yet. Just capture.
- Week 2. Translate the intake call of each pilot req into a structured rubric. Use the hiring manager's actual words, not a recruiter rewrite. Push the rubric into the ATS as the calibration artifact of record for the role.
- Week 3. Turn on auto-scorecards for the pilot reqs. Each panelist now sees the rubric, fills the scorecard from the captured interview, and the next panelist reads the previous panelist's summary before going in. The meeting that was quarterly is now per-stage.
- Week 4. Cut the quarterly calibration meeting in half. Replace the deleted half with two 15-minute weekly syncs on the pilot reqs. By the end of the month, every pilot req is on a per-interview calibration cadence and the team has the data to roll the model to the rest of the loop.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Talent calibration FAQ
How is talent calibration different from a performance review?
Performance reviews calibrate people you've already hired. Talent calibration calibrates the people you're about to hire. The first looks backward at delivered outcomes. The second looks forward at decision quality. The two practices share the same goal - a consistent, defensible bar - but they operate on different time horizons and use different evidence.
Who should be involved in talent calibration during hiring?
Every panelist, every hiring manager, and the recruiter owning the req. Optionally the function leader for senior roles and a bar-raiser for company-bar roles. Calibration during hiring is not a leadership ritual. It's the working group that interacts with the candidate.
How often should talent calibration happen?
If calibration is a meeting, quarterly is the cadence most teams settle on. If calibration is a verb, it happens on every interview. The shift from quarterly to per-interview is what this guide calls live calibration. The two cadences can co-exist, but the per-interview rhythm is what actually moves outcome metrics.
How does talent calibration apply to high-volume hiring?
It applies more, not less. High-volume hiring is where calibration drift compounds fastest because the number of interviews per week is the highest. Without a per-interview calibration rhythm, a high-volume loop quietly drops standard across the quarter and discovers it at the next review. Live calibration is the only practical way to hold the bar at volume.
How does technology support live talent calibration?
Four mechanics: live capture during the interview, auto-scorecard against the rubric, searchable cross-panel transcripts, and write-back into the ATS. With those four in place, calibration becomes a property of the loop, not a separate meeting. Without them, even the best-run quarterly calibration meeting is reading from data the loop has already moved past.
What's the difference between scorecard autofill and a calibration session?
Scorecard autofill is a tool. A calibration session is a meeting. The reason the live calibration model works is that the tool absorbs the mechanical work the meeting used to do - rating compilation, evidence quoting, panel summary - and frees the meeting to do the judgment work the tool can't: how to weight competencies, when to override, how to read the gestalt.