

Pre-employment assessment is one of the most-stacked, least-designed layers in recruiting. Most teams reach for it the way they reach for software in general: buy the test, plug it in, see what comes out.
The result is a 90-minute candidate journey for every requisition regardless of seniority. The signals that would predict performance often missing entirely.
The cost shows up downstream. Roles open longer than they should. Hires miss quota in the first two quarters. The team writes off the assessment as "not predictive" and moves on to the next vendor.
The diagnosis is rarely the assessment itself. It's that the stack was assembled, not designed.
This post breaks the work into the eight assessment categories recruiting teams have to choose between, the eight tools they reach for, and a 5-question framework for picking the right combination per role rather than stacking everything.
Why pre-employment assessment matters now
The assessment layer used to live in HR. A separate workflow, owned by people-ops, run on candidates the recruiter had already screened. That arrangement worked when hiring was slower and the cost of a bad hire was absorbed by the team. Both things changed.
Pipelines are larger, decisions are faster, and the recruiter who picked the candidate is on the hook for the outcome.
Assessment is no longer the HR layer. It's the structured-signal layer the recruiter relies on to defend a hire to a hiring manager who wasn't in the room.
When the signals are well-chosen, the case is concrete. When they're stacked-without-design, the case is a pile of scores no one trusts.
The data backs the shift. Teams using AI in hiring as a core capability, including in their assessment workflows, outperform teams that don't, and the gap is wider than most leaders assume.
The Alignment Report surveyed 505 recruiting leaders and hiring managers across North America and EMEA.
The cohort that exceeded their hiring goals reported using AI for resume screening, candidate scoring, and structured-interview analysis at materially higher rates than the cohort that missed.
Assessment design is where that gap shows up first.
The 8 categories of pre-employment assessment
Pre-employment assessment isn't one test. It's eight distinct signal layers, each measuring something different, each fitting a different role profile. Before picking tools, name the layers.
The eight categories below cover the full assessment landscape. Most roles only need two or three; almost no role needs all eight.
| Category | What it measures | When to use |
|---|---|---|
| Resume matching and application screening | Whether the application meets baseline criteria, and the patterns inside it that recruiters miss at scale. | High-volume inbound roles, screening at the funnel top. |
| Cognitive ability tests | Reasoning, problem-solving, numerical and verbal ability. | Roles where novel-problem performance is load-bearing: analysts, engineers, ops. |
| Skills assessments | Job-specific technical or functional ability: coding, writing, design, sales tactics. | When the work itself is the signal: IC roles, specialist hires. |
| Behavioral and personality assessments | Traits, work style, motivation patterns, collaboration tendencies. | Manager roles, customer-facing roles, team-fit-sensitive positions. |
| Situational judgment tests (SJTs) | How a candidate handles realistic workplace scenarios; judgment under ambiguity. | Frontline roles, customer service, healthcare, anywhere with a high-decision-volume context. |
| Structured interviews | Calibrated competency signal: same questions, same rubric, captured the same way across every interviewer. | Every role above entry level. The most-predictive assessment when run correctly. |
| Work sample tests | Performance on a representative slice of the actual job: a real task, on a clock. | Specialist roles where competency is hard to fake: writers, designers, ops analysts. |
| Background and reference checks | Employment history, qualifications, conduct, and third-party context. | Pre-offer for almost every role; varies in depth by seniority and regulatory scope. |
Treat the categories as a menu the role pulls from. A senior engineer hire might land on skills, structured interview, and reference. A frontline support hire might land on SJT, cognitive, and work sample. The mix is the design.
8 tools that earn their place in the stack
Eight tools below cover the eight categories. Two from Metaview where the structured signal layer is the work, six from specialist vendors who own a single category cleanly. Listed by where each lands in the typical funnel, not by alphabetical order or vendor weight.
1. Metaview: Application Review for application screening
Application Review is the resume-matching and pattern-detection layer at the top of the funnel. It surfaces fit signals against the role spec, flags fraud and AI-generated patterns in the application, and routes candidates by reasoning trail, not just a score.
The reasoning trail is the load-bearing part. Recruiters can see why a candidate was flagged, defend the decision to a hiring manager, and override when the trail is wrong.
It runs inside the recruiter workflow with native Integrations across Ashby, Greenhouse, Lever, Bullhorn, SmartRecruiters, and Workday, so no separate dashboard to check.
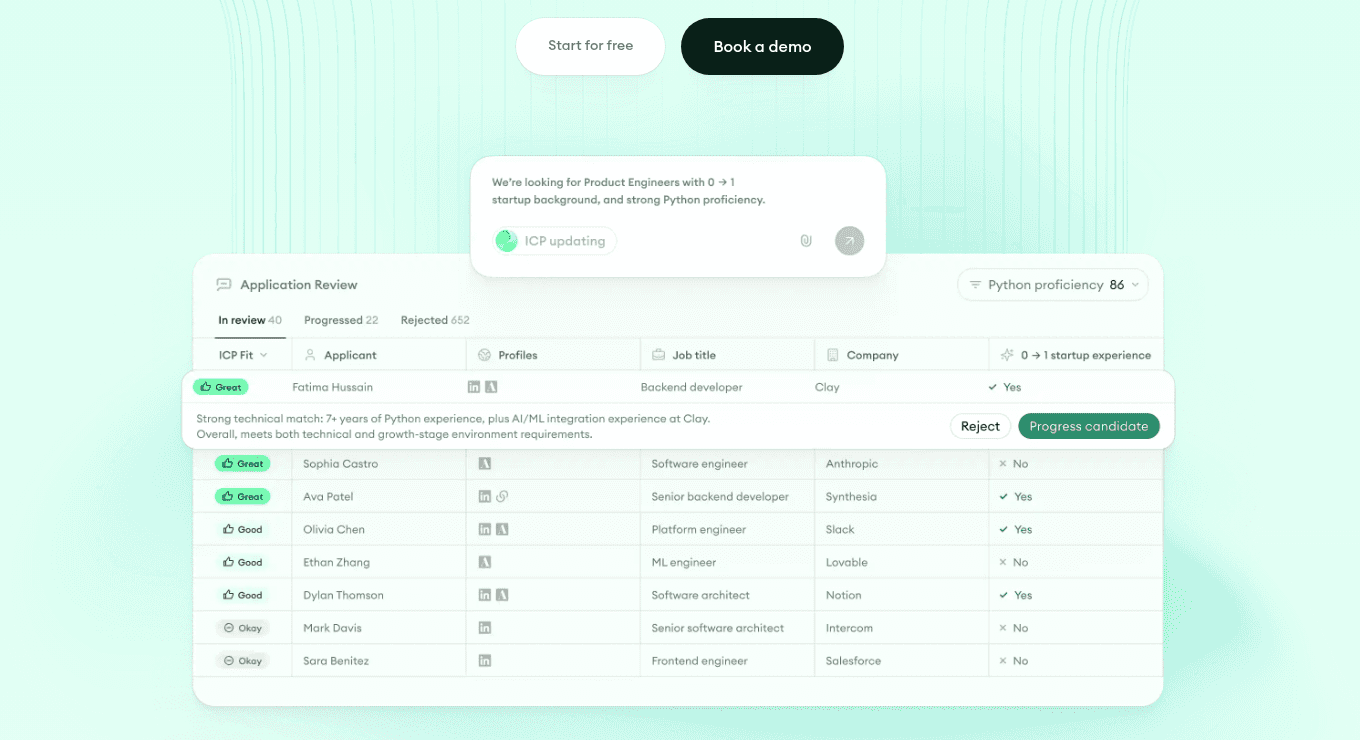
- 1ICP-fit flags surface against the role spec, ranked by signal strength.
- 2Fraud and AI-generated pattern detection flag suspect applications inline.
- 3Reject and progress actions trigger the recruiter workflow with reasoning attached.
Best for high-volume inbound roles where the recruiter needs to triage hundreds of applications per requisition without losing the qualified candidates to time decay.
Where it's weak: roles where the application volume is low enough that a recruiter can read every resume. The lift is smaller, though the fraud detection still earns its place.
What makes it different is the reasoning trail. Most application-screening tools give a score; Application Review gives a defensible explanation a hiring manager can argue with.
2. Criteria (Criteria Corp): cognitive ability tests
Criteria runs cognitive aptitude assessments, the CCAT and adjacent tests, that measure reasoning speed, problem-solving, and learning ability under time pressure.
It's the right pick when the role's failure mode is novel-problem performance: analysts who can't reframe a question, engineers who can't generalize a pattern, ops people who can't hold context across changing inputs.
Best for analyst, engineering, and ops roles where novel-problem signal is hard to fake.
Where it's weak: creative roles where cognitive aptitude under time pressure is a poor proxy for actual job performance. What makes it different is validated psychometric depth backed by 60+ years of cognitive-assessment research.
3. TestGorilla: skills assessments
TestGorilla covers 400+ job-specific skill assessments: coding, language, design, sales tactics, customer-service judgment. It's the broad-catalog skills layer.
Pick the three or four tests that match the role's job-specific abilities and run them in a single session candidates can complete on their own time.
The catalog is the strength. The lift comes from picking three tests that map to the actual work, not five tests that pad the assessment time.
Best for IC and specialist hires where the work is the signal.
Where it's weak: senior or manager hires where skills aren't the differentiator and judgment and team-fit are. What makes it different is catalog breadth across functions, with reasonable defaults for non-specialist recruiters who don't know which tests to combine.
4. The Predictive Index: behavioral and personality assessments
The Predictive Index is the long-standing behavioral-traits incumbent. The PI Behavioral Assessment maps work-style patterns; the Cognitive Assessment supplements it.
Teams use it for manager-and-above hires where traits matter more than skills: collaboration tendencies, motivation patterns, decision-making under ambiguity.
Best for manager, leadership, and customer-facing hires where work-style match is the predictor.
Where it's weak: IC technical hires where behavioral signal under-weighs skill signal. What makes it different is a manager-fit framework recruiters and hiring managers can both read without psychology training.
5. Harver: situational judgment tests
Harver runs SJT assessments: realistic-scenario decision-making for frontline, retail, healthcare, and contact-center roles.
Candidates see a workplace situation, pick from several responses, and the scoring maps against the response patterns of high-performers in similar roles at the hiring company.
Best for frontline, support, healthcare, and customer service roles with high decision-volume context.
Where it's weak: bespoke or senior roles where realistic scenarios are harder to standardize. What makes it different is a deep library of validated situational scenarios across high-volume role categories.
6. Metaview: Notetaker for structured interview intelligence
The Notetaker is the assessment layer that runs inside the structured interview rather than around it. It captures the call, extracts the competency signal against the rubric, and produces a structured scorecard the panel can review during debrief.
Across the panel, our Notetaker turns three interviewers in three calendar slots into one calibrated data layer: same questions read against the same rubric, same evidence available to every panel member at debrief.
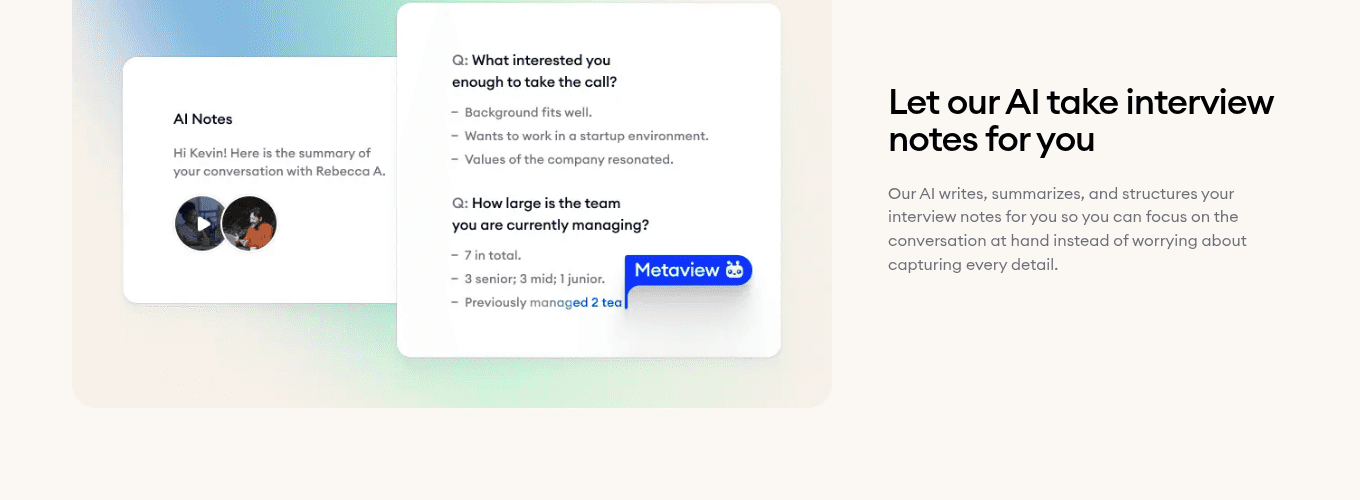
- 1Structured Q&A summary lands in the post-meeting view, anchored to the rubric.
- 2Competency chips surface the signal each answer carries.
- 3Recording and transcript stay available for the debrief, never the typed-fragment guess.
Best for every role above entry level where structured interviews are the strongest signal but the post-call reconstruction is where the signal degrades.
Where it's weak: roles where the interview is a five-minute coordination check rather than a competency evaluation. Notetaker's lift is in the structured signal layer, not the logistics.
What makes it different is that it eliminates the gap between what a panel said in the room and what shows up in the scorecard, so the debrief argues from evidence rather than memory.
7. Vervoe: work sample tests
Vervoe runs job-simulation work samples. Candidates complete a representative slice of the actual job, on a clock, scored against role-specific rubrics.
It's the closest pre-employment proxy for actual performance because the test is a piece of the work.
Best for specialist roles where competency is hard to fake: writers, designers, ops analysts, marketing operators.
Where it's weak: high-volume entry-level roles where the time investment per candidate doesn't scale. What makes it different is the highest fidelity to the actual job among the eight tools listed; the cost is the time per candidate.
8. Checkr: background and reference checks
Checkr runs background screening and reference verification: employment history, qualifications, criminal records, motor-vehicle history, drug screening. Regulatory compliance is handled across federal, state, and local jurisdictions.
It's the pre-offer signal nobody loves but nobody skips on regulated, customer-facing, or high-trust roles.
Best for pre-offer screening on almost every role with regulatory or trust-exposure.
Where it's weak: small-pipeline early-stage roles where the manual reference call is faster than the system. What makes it different is compliance scope and integration coverage at scale. The work-product matches what legal teams will accept.
How to choose: 5 questions for your assessment mix
The tools above cover the eight categories. The five questions below pick which two or three to combine for any given role. Run them as a sequence, in order. Each question narrows the menu the next one picks from.
| Question | What to look for in the answer |
|---|---|
| 1. What does this role's most-common failure mode look like? | Turnover at 90 days points to behavioral or SJT signal. Missed quota points to cognitive or work-sample signal. Map the failure to the category that would have caught it. |
| 2. What's the candidate-experience budget per stage? | Pre-application stays under 10 minutes. Post-recruiter-screen stays under 45 minutes. Pre-panel stays under 90 minutes. Total stack stays under 2.5 hours including the interviews. Anything longer loses qualified candidates to faster-moving competitors. |
| 3. What's the legal-defensibility scope? | Regulated, customer-facing, or trust-exposed roles need validated and audit-trail-bearing assessments. Skip vendor tools that can't produce defensible reports. |
| 4. What scales to your hiring volume? | High-volume frontline roles need fast, automated, self-serve assessments. Low-volume specialist roles can afford richer work-sample tests with longer per-candidate review. |
| 5. What integrates with the rest of your stack? | An assessment that lives in a separate dashboard the recruiter has to check is an assessment that gets skipped on busy days. Native ATS and recruiter-workflow integration is the difference between adopted and shelved. |
The five questions don't replace judgment. They structure it. Most recruiters can name their role's failure mode in two sentences. The rest of the framework just confirms that the mix they reach for is the one that maps to the failure.
When the framework lands cleanly, the assessment stops being a stack of vendor tools and starts being evidence-based assessment the recruiter and hiring manager argue from together.
We elevated from gut-feel recommendations to evidence-based insights, creating a faster, clearer, and more data-driven experience for everyone involved. Every scorecard and report looks and sounds consistent, regardless of who prepared it.”
The mix beats the bundle
Pre-employment assessment is a foundational requirement for fast, fair, and effective hiring at scale. The teams winning at it aren't running every test on every candidate.
They're picking two or three signals per role, matched to the failure mode that role most commonly produces, scaled against the candidate-experience budget the funnel can absorb.
Three moves this week. Audit the current stack against the eight categories above: which signals is each role getting, and which are missing? Run the 5-question framework on one open requisition and rebuild the assessment mix for that role.
Swap one assessment that hasn't been earning its place for a better-fit alternative from the same category. The mix beats the bundle. Design picks the mix.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Frequently asked
How do I choose the right pre-employment assessments for my roles?
Start from the role's most-common failure mode and reverse-engineer the assessment that would have caught it. Turnover at 90 days usually points to behavioral or SJT signal. Missed quota usually points to cognitive or work-sample signal. The mapping isn't perfect, but it narrows the menu fast.
When in the hiring process should assessments be used?
Sequence by depth. Pre-application gets the resume match and a short skills screen. Post-recruiter-screen gets cognitive or behavioral signal. Pre-panel gets the work sample or structured interview. Pre-offer gets background and reference. The stages narrow as the candidate progresses; depth grows where the signal earns its place.
How long should a pre-employment assessment take?
Budget by stage rather than by total. Practitioner defaults: pre-application stays under 10 minutes, post-recruiter-screen under 45 minutes, pre-panel under 90 minutes, total stays under 2.5 hours including the interviews themselves. Stacks longer than that lose qualified candidates to faster-moving competitors well before the offer.
Can pre-employment assessments hurt candidate experience?
Three patterns are the usual culprits. Assessment-before-context, where the candidate tests before they understand what the role is. Assessment-without-feedback, where the test runs without telling the candidate what happened with their results. Assessment-stacking, where three or four tools run in a single stage. Avoid those, and the assessment becomes part of the candidate experience rather than friction in it.
How do I measure whether my assessments are working?
Correlate assessment scores against six-month performance ratings and twelve-month retention for hires across one to two years of pipeline. If the correlation runs below 0.3, the assessment isn't predictive for your roles and the budget is better spent elsewhere in the funnel. The validation work is overhead, but it's how you tell a working assessment apart from an expensive one.
Do I need different assessments for different roles?
Usually. IC roles lean on skills assessments and work samples. Manager roles lean on SJTs and behavioral assessments. Senior leadership leans on structured interviews and reference depth. The reason the framework above asks about failure mode is that role types fail in different ways, and the assessment mix has to track that variation rather than treat every requisition the same.