

Most interview feedback is written too vague to act on. Recruiters know it, candidates know it, hiring managers know it. The artifact still gets shipped that way.
The document that connects what the candidate said to what the team decided is broken in most hiring systems, and feedback is that document.
Interview feedback is the artifact your hiring loop runs on. It gets captured per interviewer, structured against an interview rubric, shared across the team, and delivered to the candidate. When any link in that chain breaks, the loop breaks. Capture beats memory every time.
This post walks the five moves that separate feedback that helps from feedback that hurts, names the trust-gap diagnosis under the failure mode, and shows the Metaview surfaces (AI Notes, Multi-Source Summaries, and Reports) that scale the system past a handful of senior hires.
Why interview feedback breaks down
Most hiring teams know feedback matters. They also know they're not doing it well. The reason isn't effort. It's the system.
According to Metaview's 2026 AI Hiring Alignment Report, surveying 505 recruiting leaders and hiring managers across North America and EMEA, the trust gap is structural.
Customer data shows the operational cost of the gap, and the lift when the structured-capture layer is in place.
That surface-vs-reality gap doesn't come from anywhere mysterious. It gets built one missed signal at a time, every time a feedback artifact is too vague, too late, or missing entirely.
Feedback is where the signal goes when it doesn't survive the interview. Memory fades by Friday. Notes get rushed because the next call starts in eleven minutes. Three interviewers walk out with three different versions of the same conversation.
The input layer fails first, and the artifact that the team would have shared, calibrated against, and built future hires on never gets written.
Get that artifact right and the loop closes on every hire. Get it wrong and the same biases, missed signals, and post-call regrets compound across every req.
What separates feedback that helps from feedback that hurts
Five moves separate feedback that compounds across reqs from feedback that gets written once and forgotten. None of them are new. All of them get easier to hold once the structure is in place.
1. Anchor it in what the candidate said
The most useful interview feedback quotes the candidate. Not the interviewer's impression of the candidate. The phrase, decision, or trade-off the candidate named in the room.
"I scoped the project at three weeks but my manager wanted two" is feedback the candidate can act on. "Good problem-solving skills" is a label, not feedback.
The first is specific, anchored in evidence, and reusable in future calibration. The second is filler that says nothing the candidate didn't already know.
The blocker isn't the writing. It's the capture. By the time the post-call notes get written, the exact phrasing is gone, and the structured note becomes a fuzzy summary instead of a record.
The simplest fix is a one-line note per scorecard competency, written before the panel kickoff and handed to every interviewer. Anchor every observation to a phrase or a behavior, not an impression.
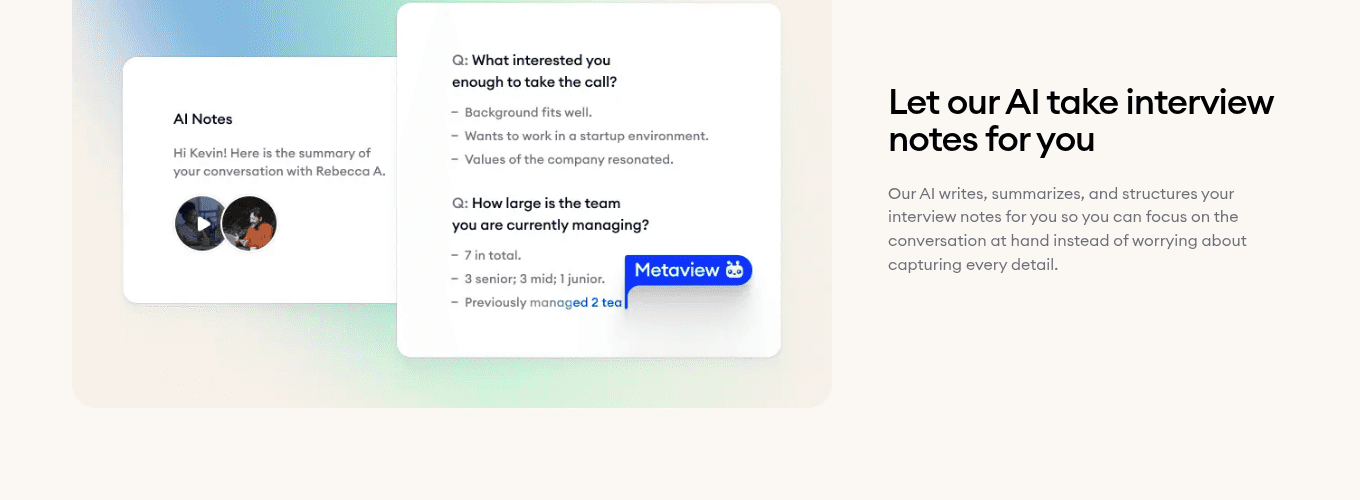
- 1Per-question structured capture maps the candidate's answers to each scorecard competency.
- 2Verbatim quotes get attached to the rubric lines they support, so feedback writes from evidence.
- 3Topic chips let interviewers jump to the exact moment a competency surfaced in the call.
2. Tie every observation to a scorecard line
Specific feedback that lives outside the rubric still reads as opinion. Map every line of evidence back to a scorecard competency the team agreed on, and the feedback becomes defensible.
This is what separates "we liked her" from "she demonstrated four of the five behaviors we're hiring for at the senior level." The first is preference. The second is a hiring decision the team can defend, calibrate against, and learn from.
Feedback that doesn't tie to the rubric also doesn't help candidates improve. A candidate who hears "we went with someone who was a better fit" can't act on that.
A candidate who hears "we were looking for stronger technical architecture experience at the staff level, and you mostly described mid-level execution work" knows what to develop.
Add an "evidence" column to the scorecard template. Every numerical score gets a one-sentence evidence note before the debrief opens. If interviewers can't fill the column, the score is too high.
3. Balance strengths and development areas
Even rejected candidates earn balanced feedback. Not because politeness demands it, but because structure does. Balance is structural, not stylistic.
A feedback artifact with only weaknesses is incomplete signal. The team needs to see what worked alongside what didn't, because what worked is information the next search might match against.
Strengths preserved in the rubric become inputs to the next sourcing brief. Weaknesses preserved become guardrails.
For candidates, balance turns the rejection into something usable. They walk away with a clear picture of what to develop and what to lean into. That's the difference between a candidate who recommends your company to their network and one who doesn't.
The practical version: cap candidate-facing feedback at one to three strengths and one to three development areas, in that order. The cap forces interviewers to pick the most important signals instead of listing every micro-observation.
Hand the candidate the capped version, not the internal debrief notes.
4. Run from one rubric across every interviewer
Consistency comes from the schema, not the meeting. Calibrate in the schema: same rubric, same competencies, same agreed-on definitions of what each scoring level means per skill.
The debrief becomes a check on whether the rubric got applied evenly, not a debate about what "good" means.
Interviewer drift is the silent killer of feedback quality. Two interviewers on the same panel can give the same candidate a 4 and a 2 if the rubric is fuzzy. The candidate gets contradictory feedback, the team makes a coin-flip decision, and the next req starts the same way.
Calibration sessions before the first panel, plus a quarterly check on where individual interviewers are drifting, fix this at the source. The rubric is the long-term investment. The feedback is the short-term payoff.
Run a 30-minute calibration session on next week's most active req. Walk through two sample answers as a team and agree on what each scoring level means for that skill. Capture the agreement in writing so the rubric updates persist.
5. Deliver feedback before the signal goes cold
Feedback delivered three weeks later isn't feedback. It's an apology. The candidate has moved on, the team has forgotten, and the artifact that should have carried forward into the next req sits in a Google doc nobody opens.
Forty-eight hours, no later, to the candidate. Immediately to the team. The 48-hour SLA isn't aspirational; it's how late the artifact can be before the signal degrades and the trust gap widens.
Timing also signals respect. Candidates who get feedback fast read it as: this company values my time and my application. Candidates who get nothing read it as: they were never serious. That second read travels.
How Metaview makes feedback fast, evidence-based, and consistent
The five moves above don't require Metaview. They require structure. Metaview is what makes the structure hold at scale, past the first few thoughtful hires and into the hundreds of reqs the team will run this year.
- Interviewer types notes during the call, half-listening to the candidate
- Post-call summary is a fuzzy recall written 30 minutes later
- Each interviewer's scorecard reads differently for the same candidate
- Debrief opens with "what did you think?" before evidence is locked
- Candidate-facing feedback gets drafted from memory, days later
- Notetaker captures the call so the interviewer stays present
- Structured summary lands per scorecard line, sourced to the transcript
- The rubric is applied from one schema across every interviewer
- Debrief opens after every panelist has locked in their scorecard
- Candidate-facing feedback drafts from the structured note in minutes
The lift compounds across the surfaces. The Notetaker captures the call so the artifact starts with verbatim evidence, not memory.
Application Review structures the inputs across the panel so no interviewer is missing the rubric. Multi-Source Summaries balance the perspectives so the team sees the whole picture before the debrief opens.
And Reports surfaces who's drifting on the rubric so calibration becomes a continuous practice.
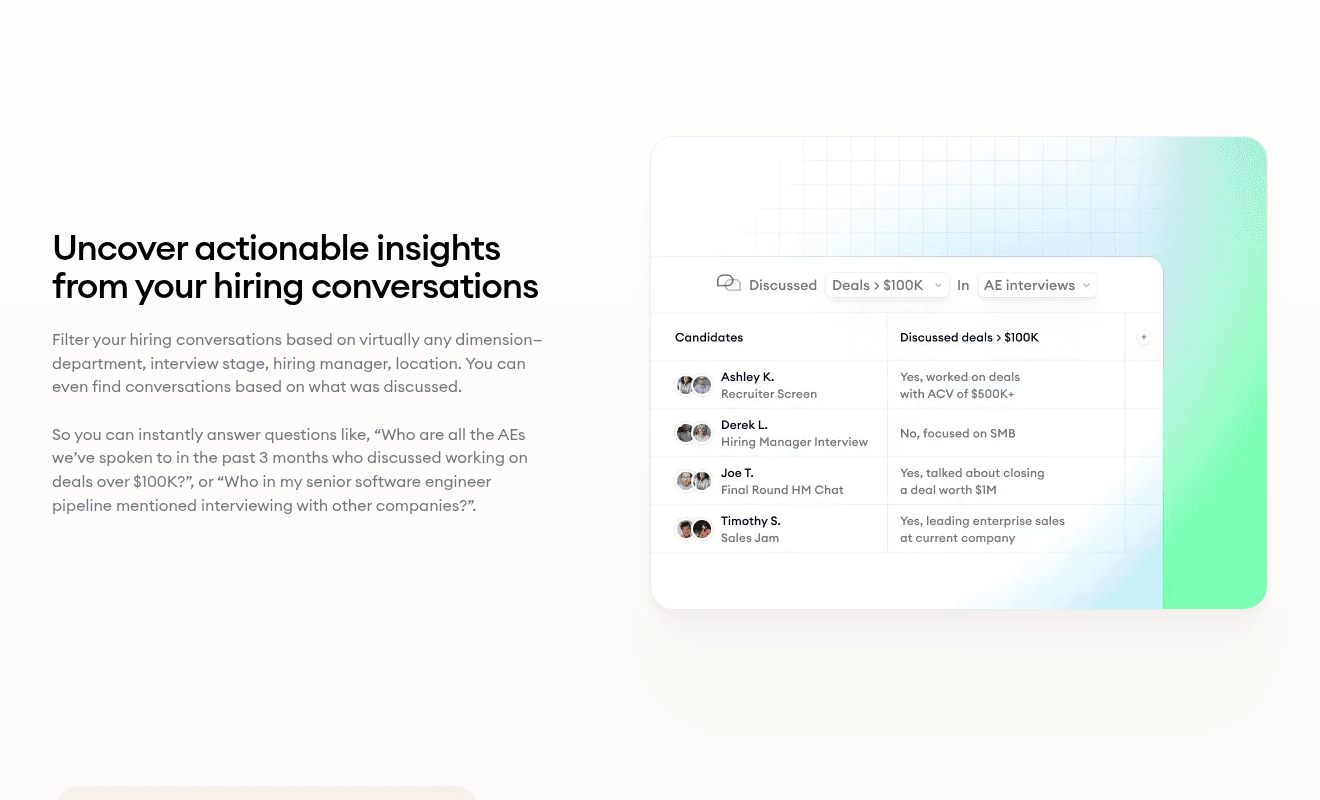
- 1Cross-panel themes get pre-surfaced before the debrief opens.
- 2Strengths and growth areas land balanced per panelist, ready to draft.
- 3Recommended next steps for offer prep get framed against the rubric.
Multi-Source Summaries are where the feedback artifact starts compounding across interviewers. Each panelist's structured notes feed a single cross-panel view that surfaces themes, gaps, and disagreements before anyone speaks.
The debrief becomes a check on the evidence, not a reconstruction of who said what.
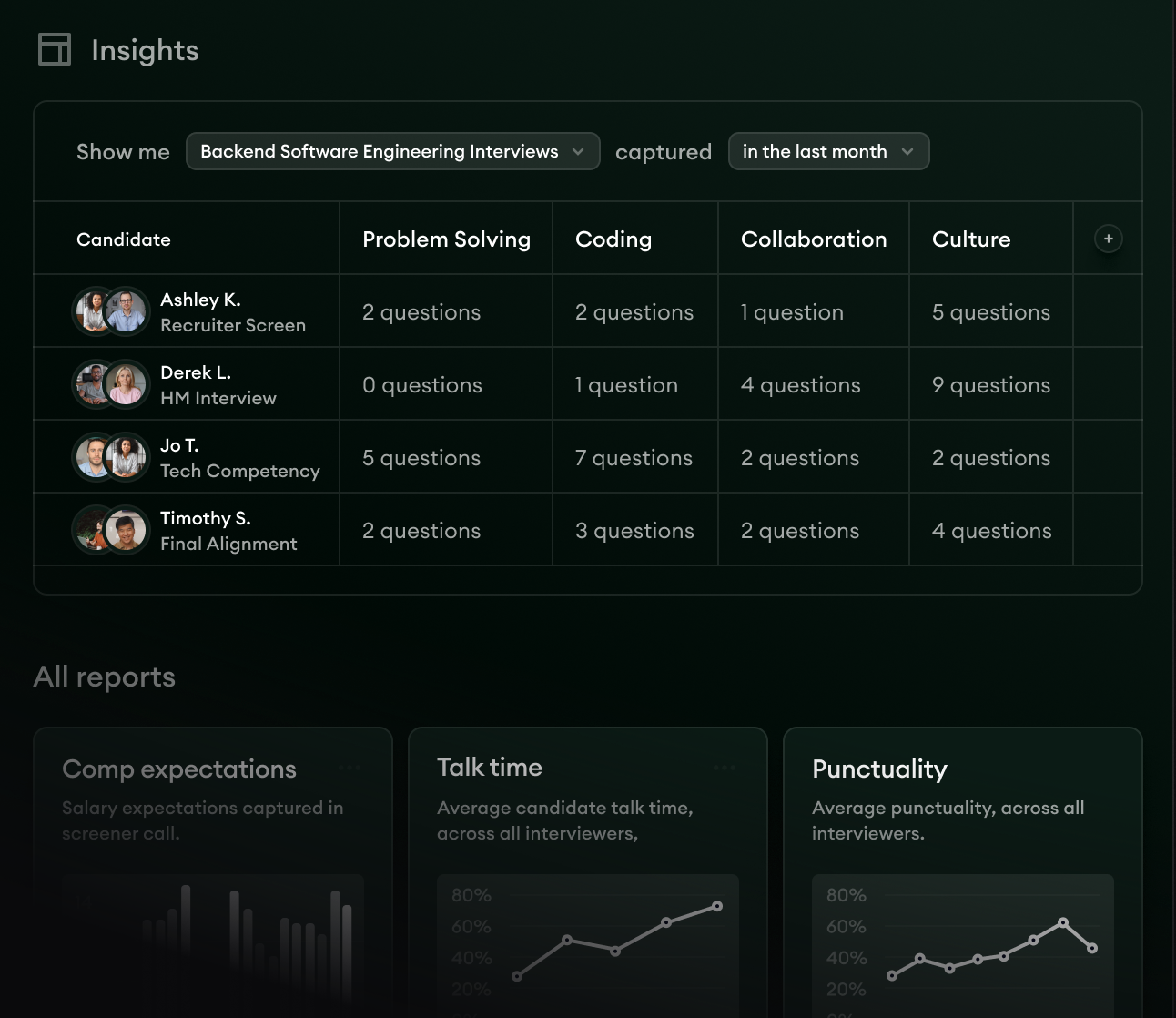
- 1Skill-by-skill capture rolls up across every interview the team has run this quarter.
- 2Per-interviewer scoring distribution shows where individual scorers run hot or cold.
- 3Per-candidate rollup makes uneven feedback coverage visible before the debrief.
When the inputs are structured and the surfaces compound, the manual reconstruction goes away.
Recruiters spend the saved time on the parts of feedback delivery only humans can do: the tone, the empathy, the contextual framing of a hard message.
The team at Airalo, scaling hiring globally across 80+ countries, named the shift specifically.
We've completed over 1,900 calls using this platform, saving 77 full workdays. We're not just automating note-taking, we use the multi-source feature so each interviewer goes in unbiased but informed enough to cover new ground.”
Make interview feedback a core strength
Interview feedback is the artifact your hiring loop runs on. Get the artifact right and every hire compounds against the last one. Get it wrong and the same biases, missed signals, and post-call regrets cycle through every req.
The output of every interview is the feedback document, not the meeting itself.
Run the five moves on next week's most active req. Anchor in evidence, tie to the rubric, balance the read, calibrate against the schema, deliver in 48 hours.
Each move compounds against the one before it. The loop closes here, and the next req opens with better data than the last one did.
Frequently asked
How specific should interview feedback be?
As specific as the candidate could put on a future resume. Quote a phrase they used, name a behavior they demonstrated, or describe a trade-off they walked through. Length matters less than precision: three sentences of evidence-anchored observation beat a paragraph of impressions. For candidate-facing feedback, cap at one to three strengths and one to three development areas. Longer lists dilute the signal.
Should every candidate receive interview feedback?
Tier it by stage. Final-round candidates always get personalized feedback. Post-interview candidates get specific feedback by default, even on rejections. Application-stage rejections can ship as templated feedback batched by req, naming the specific criteria that didn't match. The structured note from each interview is what makes the tiering practical, because most of the writing is already done.
How fast should interview feedback be delivered?
Within 48 hours to the candidate and immediately to the team. If the panel debrief hasn't happened yet, ship an interim message to the candidate first ("we're still gathering input from the panel and will follow up by Friday") so the silence doesn't read as ghosting. The 48-hour SLA is what holds the trust gap closed; longer than that and the candidate has already moved on.
Who should write the feedback the candidate sees, recruiter or interviewer?
Interviewer writes the substance, recruiter edits for tone and delivers. The interviewer holds the subject-matter accuracy and the rubric-anchored evidence. The recruiter holds the candidate-experience polish and the brand voice. That ownership split keeps the feedback specific without making it feel like a clinical evaluation document.
How do you keep feedback consistent across interviewers?
Calibration happens in the rubric, not in the meeting. Run a quarterly calibration session where the team walks through two sample answers and agrees on what each scoring level means per skill. Then surface interviewer drift continuously through the Reports view, so calibration becomes a check instead of an event. The compounding makes year-two hires better than year-one hires using the same rubric.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.