

The principles of good interviewer training haven't changed in years. What's changed is what carries them.
Most teams still run interviewer training the same way: a kickoff doc, a shadow session, a recap email, and a quarterly recalibration meeting that nobody quite remembers afterward.
The five principles every program leans on are still right: intentional, ongoing, peer-driven, personalized, and rigorous. What's changed is that the interview itself can now carry them.
Most recruiting teams already record interviews and run AI capture against them. Most still treat interviewer training as a separate workstream from the recorded interviews they're capturing.
The training program lives in one tool, the interview data lives in another, and the two don't talk.
This is the playbook for closing that gap, and the in-product surfaces that make each step stick.
We want our candidates to feel like they just got in a room with a whiteboard to solve an interesting problem with someone that they respect.”
That outcome doesn't come from interviewer instinct. It comes from a training program that runs on the same data layer as the interview.
Why interviewer training only sticks when the mechanism is shared
The case for interviewer training has always been about raising the bar consistently: time-to-hire, candidate experience, hiring quality, bias reduction, business velocity.
Those outcomes are still the prize. The argument hasn't changed.
What's changed is that "consistently" is now measurable in a way it wasn't before. Every interview can be captured, structured, and scored against the same rubric.
When that happens, the team's variance becomes visible. A calibration session can compare two scorecards from the same candidate side-by-side. A coaching conversation can reference an interviewer's last ten panels, not the trainer's recollection of their last one.
This shift matters most for the People Ops or TA leader running the program at scale. The principles you brief on Monday only stick when the artifact reinforcing them is the same artifact the interviewer reaches for on Tuesday.
Training that runs in a different tool from the interview leaks signal between the session and the next call.
The five principles still hold. What follows is how each one becomes operational once the interview data layer carries it.
Where training programs leak signal
Most interviewer training programs were designed before recording, transcripts, and structured scorecards became the default.
The artifacts the program produces (a slide deck, a calibration scorecard, a coaching note) live in a separate place from the artifacts the interviewer uses (the live interview, the post-call notes, the team scorecard).
The before-and-after looks like this once Metaview becomes the training data layer:
- Training on hypothetical candidates from a slide deck
- Calibration sessions running on the trainer's recall of last quarter
- Shadow sessions limited to who's free the same hour
- Coaching conversations grounded in anecdote
- Recalibration once a year, when someone notices drift
- Training on real recordings from last week's panels
- Calibration on side-by-side scorecards of the same candidate
- Async shadow against the structured interview artifact
- Coaching grounded in pattern-level drift across panels
- Drift surfaced continuously through Reports
The shift isn't about more content. It's a shorter distance between the training program and the next interview the interviewer runs.
The 5-step training program
The program runs in five moves. Each one assumes the interview data layer is the medium, not just the recording.
Step 1: Anchor the rubric before the program starts
The rubric is the curriculum. If the training program calibrates against a different scorecard than the one interviewers will use on their next call, the training doesn't transfer.
Anchor the interview rubric to the role's competencies before the first training session lands. Tie each competency to two or three signal-bearing questions the interviewer will ask.
Give every competency a 1-3-5 anchor for what the answer looks like at each level. The rubric makes the program portable across interviewers, panels, and quarters.
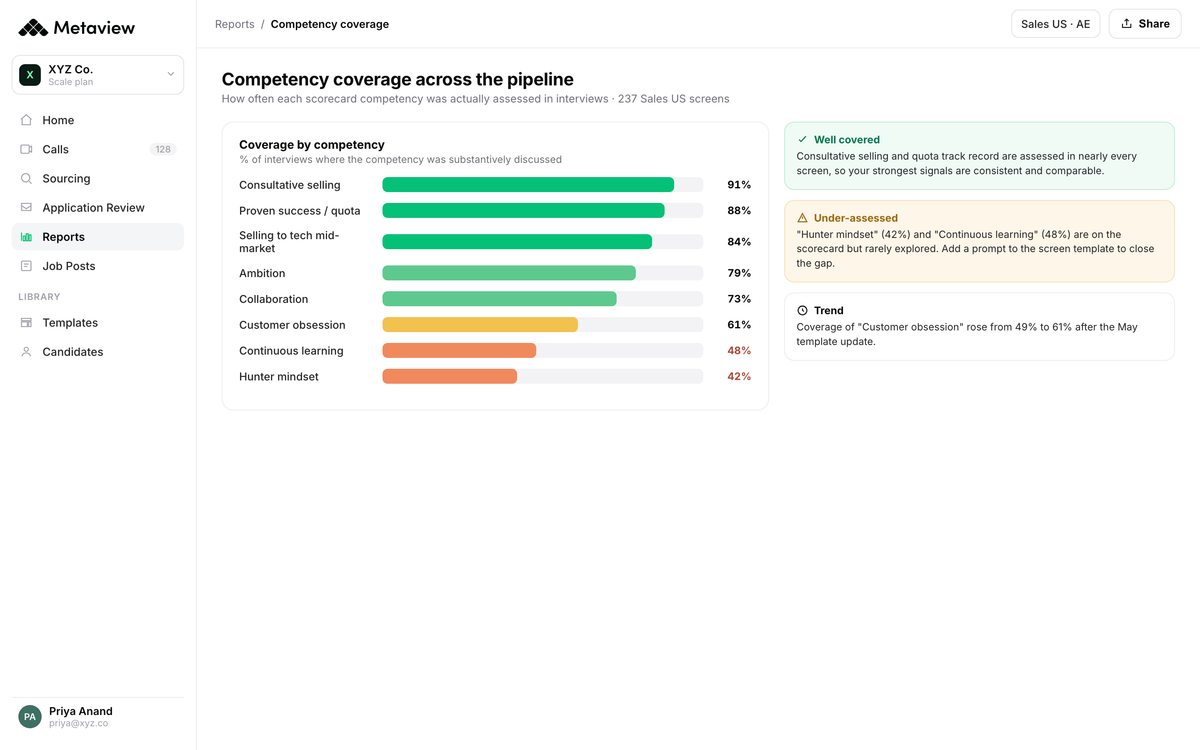
Use Reports to confirm the rubric is the one the team is scoring against. If the competencies in the program don't match the ones the team scores on, fix the rubric before you train another interviewer against it.
Step 2: Shadow real interviews, not theoretical ones
Training rooms with a hypothetical candidate don't transfer. Reviewing the recording of a real screening call from last week collapses the abstraction.
The shadow session becomes a structured artifact instead of an hour someone has to attend live.
With AI Notetaker capturing every interview, a trainer can hand a new interviewer the last three panels for a role, mapped to the rubric, with the candidate's own answers preserved verbatim.
The new interviewer sees what good questions look like, what weak follow-ups sound like, and where the panel scored what.
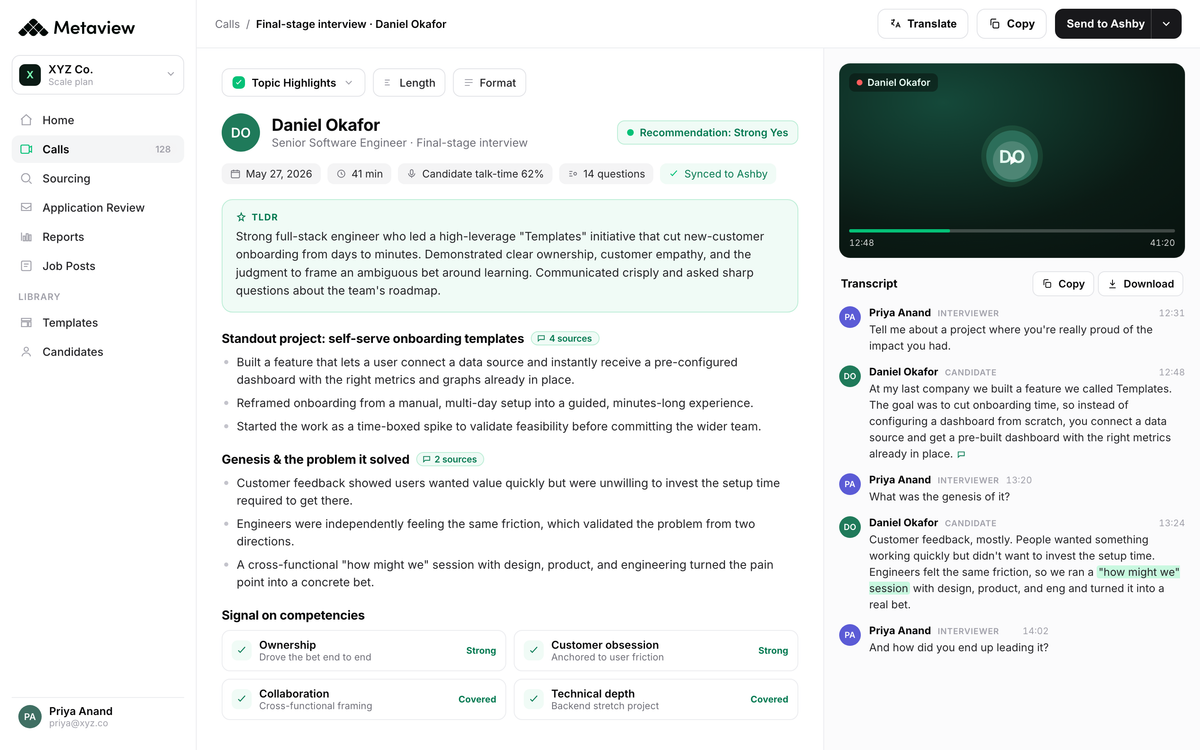
Step 3: Calibrate by comparison, not by lecture
Side-by-side scorecards from two interviewers on the same candidate surface drift faster than any calibration lecture.
The trainer's job is to facilitate the comparison, not to deliver the answer. When two scores diverge, the conversation goes to the rubric anchor and the evidence in the recording, not to whose instinct was sharper.
This is the move most calibration sessions skip. A trainer presents the rubric, walks through a hypothetical, and asks if there are any questions.
There usually aren't. The drift shows up two weeks later in real panels, when no one is watching for it.
Step 4: Coach by evidence, not by anecdote
One call is noise. Drift across ten panels is the signal.
Coaching an interviewer on a single call usually surfaces a story the interviewer can rationalize. Coaching on a pattern across their last ten panels surfaces a behavior they can fix.
Application Review and Reports surface interviewer-level patterns the trainer needs to see.
Who's consistently scoring a competency a half-point below the panel mean. Who's asking deep follow-ups on three of five rubric anchors and skipping the other two. Who needs a refresh on the scoring scale before their next loop.
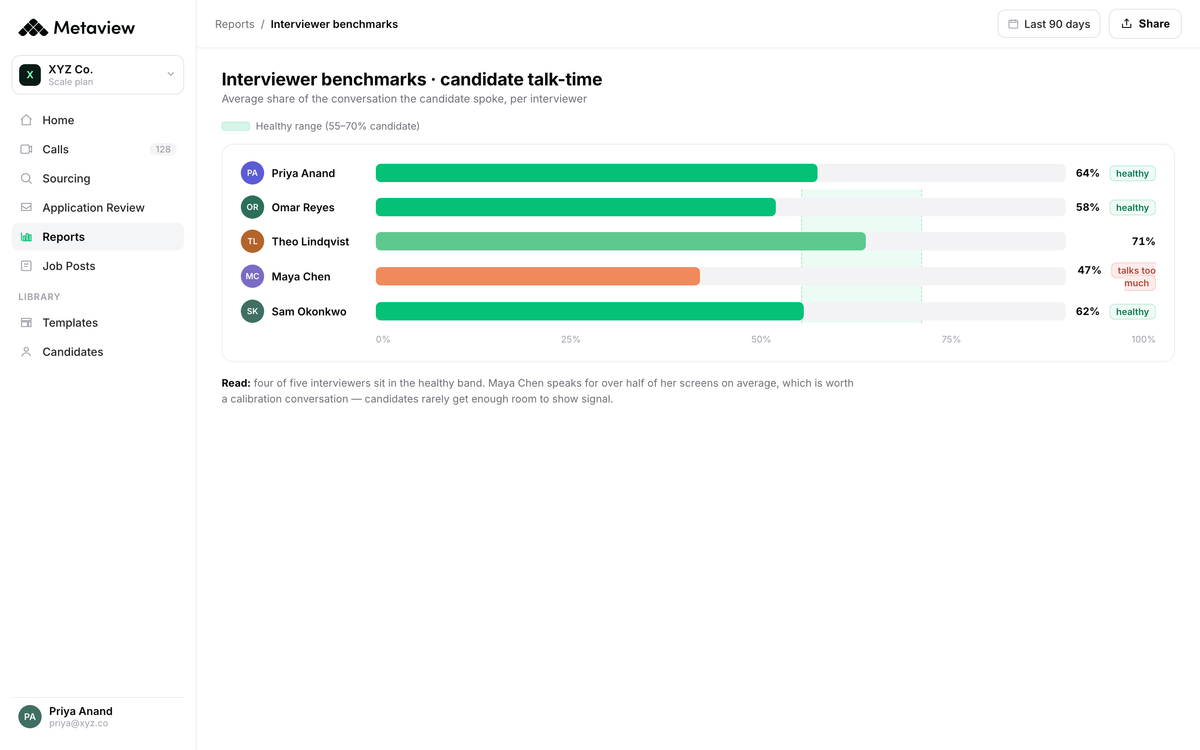
The coaching conversation moves from "I think you might be running long on the technical section" to "you've scored Java questions a half-point below the panel mean across your last eight panels, let's pull two of them up and look at the follow-ups together."
Evidence makes the conversation specific; specific is what makes it stick.
Step 5: Close the loop inside the workflow
Every coaching conversation generates a behavioral change. The change has to land where the next interview happens.
That means the training artifact (the calibration note, the rubric edit, the new question set) gets routed back into the interview workflow, not stored in a separate learning system.
This is where most training programs lose the most signal. The LMS holds the calibration notes. The ATS holds the scorecards.
The interview tool holds the recordings. None of them talk to each other, and the artifact a coach wrote on Wednesday doesn't reach the interviewer on Thursday's panel.
When the rubric edit, the new follow-up question, and the coaching note all live inside the same workflow the interviewer uses to run the next call, the training program stops being a separate workstream. It becomes the way the team interviews.
What customers see when the program holds across the team
The lift from a training program that runs on the interview data layer shows up in the team-level numbers.
The teams that run alignment well, with aligned rubric, calibration, coaching, and workflow, pull ahead.
The training program is one of the levers that turns the alignment dial.
When every interviewer runs the same rubric, captures the same kind of evidence, and gets the same kind of coaching, the cross-functional relationship between recruiting and the hiring manager has the substrate it needs.
Reducing interviewer bias and improving individual craft both come out of the same data layer.
Interviewer-level insights pinpoint who's consistently compliant, who's asking the right questions, and who needs coaching.”
Deel's lift is what coach-by-evidence looks like as a program. The trainer no longer guesses where the drift sits, the data points to it.
That specificity is the outcome every program names. The mechanism is what makes it repeatable.
The program lasts when the mechanism is shared
Interviewer training stops being a workstream you run in isolation when the data layer it runs on is the same one your interviewers already use.
The five principles still describe the program. The five moves above describe the mechanism.
The teams that get this right share one thing: they treat the training program as the operating system of their interview process, not as the orientation week.
The program lasts when the mechanism is shared, and the mechanism gets shared when every recorded interview, every scorecard, and every coaching note routes through the same place.
Bring Metaview into your hiring stack.
Live notes, structured scorecards, and ATS sync - set up in under 10 minutes.
Frequently asked
How is interviewer training different from interviewer calibration?
Calibration is one step inside the broader training program. The program is the cadence, the content, the audience, and the artifact that carries it forward. Calibration is the recurring move that keeps the rubric anchored across interviewers. A team can calibrate without running a full training program; a training program without recurring calibration drifts within a quarter.
How much time does this program take to run at scale?
Week one for a new cohort of five interviewers takes roughly three hours of trainer time: rubric anchor, first shadow session, first calibration. After that, plan on about thirty minutes per interviewer per week for the first two months, then closer to fifteen minutes a month once Reports surfaces drift continuously. The total time budget is smaller than most quarterly recalibration programs.
Does this work if my team is on Greenhouse, Ashby, Lever, or Workday?
The five-step program runs end-to-end on every ATS Metaview supports natively, including Greenhouse, Ashby, Lever, Workday, and Bullhorn. New connectors ship monthly. Check the integrations page for the current roster, and if a stack-specific gap blocks you from setting up the program, flag it to your account team early so the roadmap can carry the dependency.
Who owns the program, People Ops or the hiring manager?
People Ops owns the program design, the cadence, the curriculum, the rubric anchor, and the recurring calibration sessions. Hiring managers own the per-team coaching: the conversation that closes a specific interviewer's specific drift on a specific competency. Reports surfaces team-level drift to People Ops and interviewer-level drift to the hiring manager, so each owner sees the layer they're responsible for.
Is this program the same for new hires and tenured interviewers?
Same program, different surface frequency. New interviewers land on the full five-step cadence for the first eight weeks with denser shadow sessions and faster feedback loops. Tenured interviewers move to a monthly cadence of Reports-surfaced drift signals plus a quarterly calibration session. The mechanism doesn't change; the dial does.